Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
简介
Apache Flink 是一个开源的流处理框架和分布式处理引擎,用于对无界和有界数据流进行状态计算
Flink 具备的能力
- 正确性保证:精确一次的状态一致性、事件时间处理、复杂的延迟数据处理
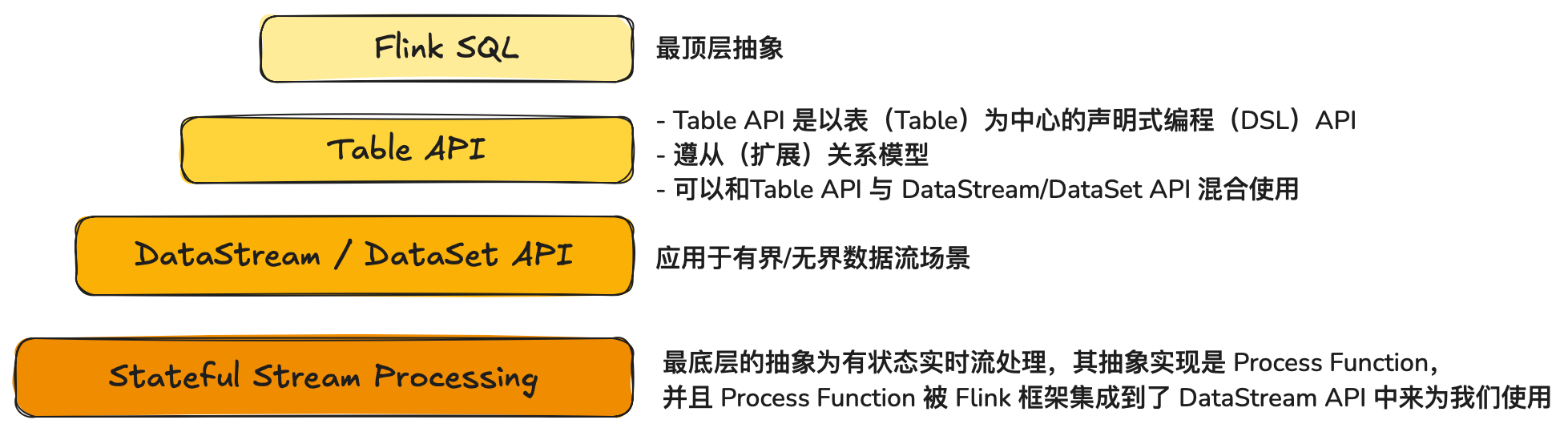
- 分层 API:流数据和批数据上的 SQL、DataStream API、ProcessFunction(时间与状态)
- 运维:灵活部署、高可用性设置、保存点
- 扩展性:横向扩展架构、支持非常大的状态、增量检查点
- 性能:低延迟、高吞吐量、内存计算
Flink核心
- 状态 + 时间(水位线) + 事件驱动
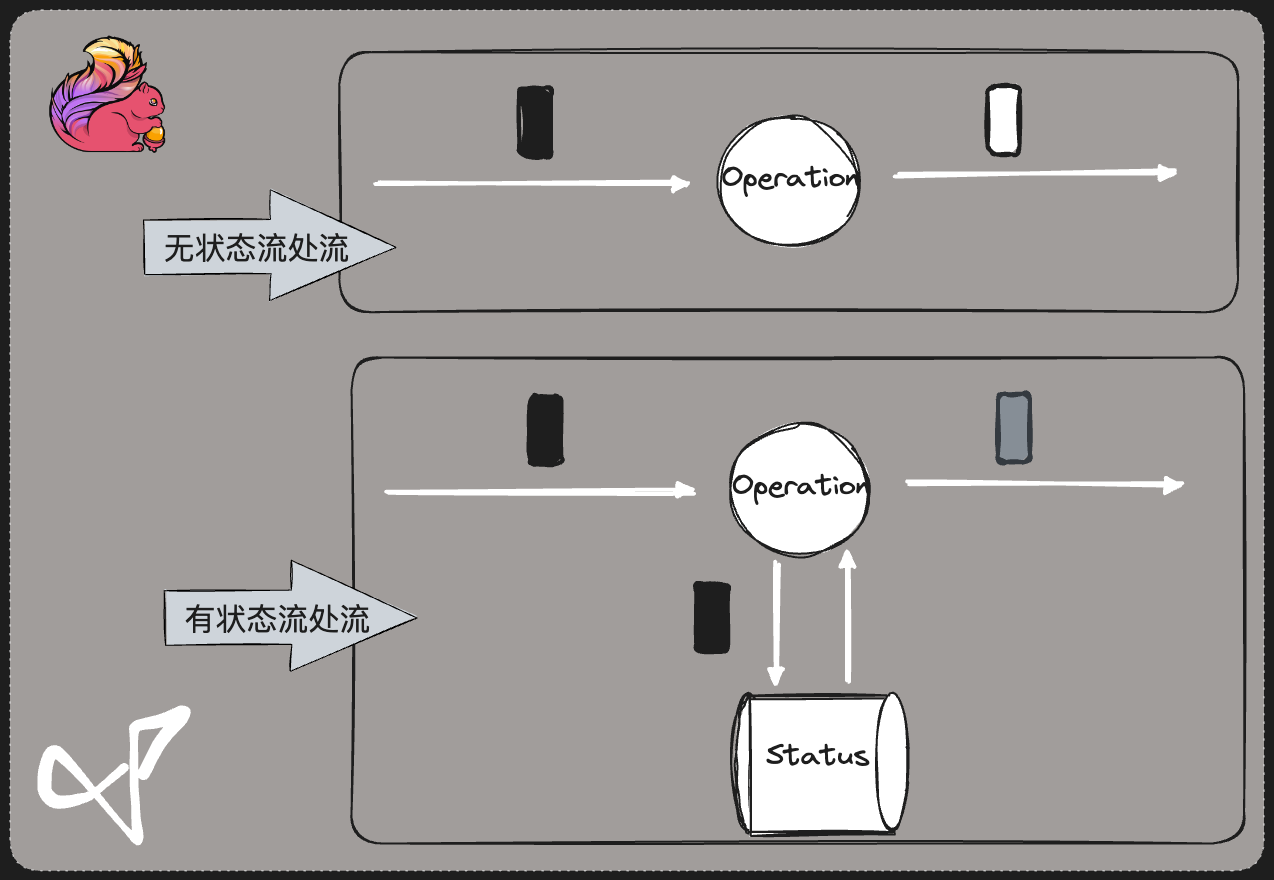
- 有状态 : 输入值 + 初始值 = 输出值
- 无状态 : 输入值 = 输出值
Flink 主要特点
流数据更真实地反映了我们的生活方式- 低延迟(Spark Streaming 的延迟是秒级,Flink 延迟是毫秒级)
- 高吞吐(阿里每秒钟使用Flink 处理4.6PB,双十一大屏)
- 结果的准确性和良好的容错性(exactly-once)
Flink 其他特点
- 支持事件时间(event-time)和处理时间(processing-time)语义
- 精确一次(exactly-once)的状态一致性保证
- 低延迟,每秒处理数百万个事件,毫秒级延迟(实际上就是没有延迟)
- 与众多常用存储系统的连接(ES,HBase,MySQL,Redis⋯)
- 高可用(zookeeper),动态扩展,实现7*24 小时全天候运行
使用场景
- 事件驱动型应用程序
- 流式与批量分析
- 数据管道与 ETL(提取、转换、加载)
Flink vs Spark Streaming区别
数据模型
- Spark 采用’RDD’模型,Spark Streaming 的DStream 实际上是一组组小批数据RDD的集合
- Flink ‘基本数据模型’是数据流,以及事件(Event)序列(Integer. String. Long. POJO Class)
运行时架构
- Spark 是’批计算’,将DAG 划分为不同的Stage,一个Stage完成后才可以计算下一个Stage
- Flink 是’流计算’,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
数据架构演变
-
事务处理 OLTP
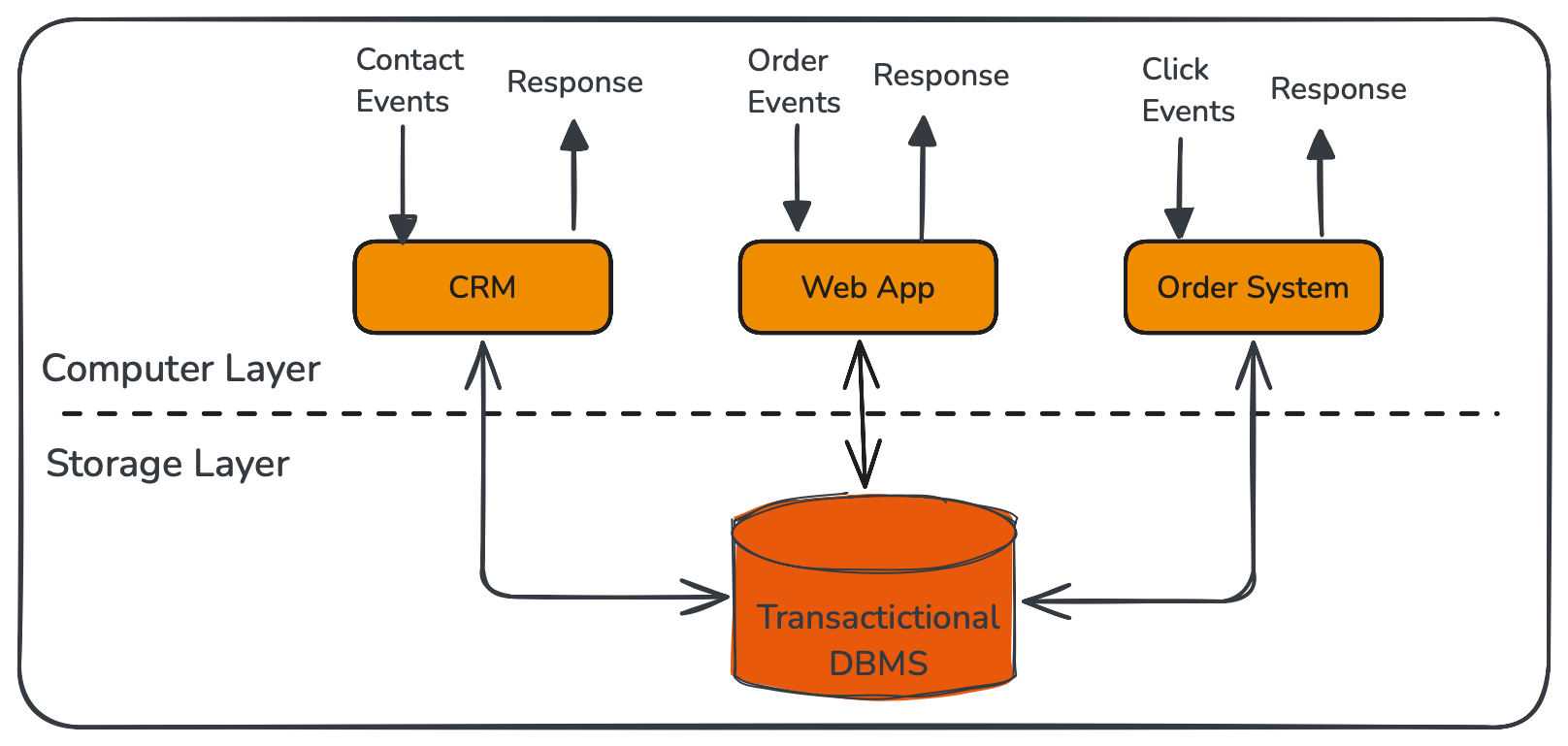
-
分析处理 OLAP : 将数据从业务数据库复制到数仓,再进行分析和查
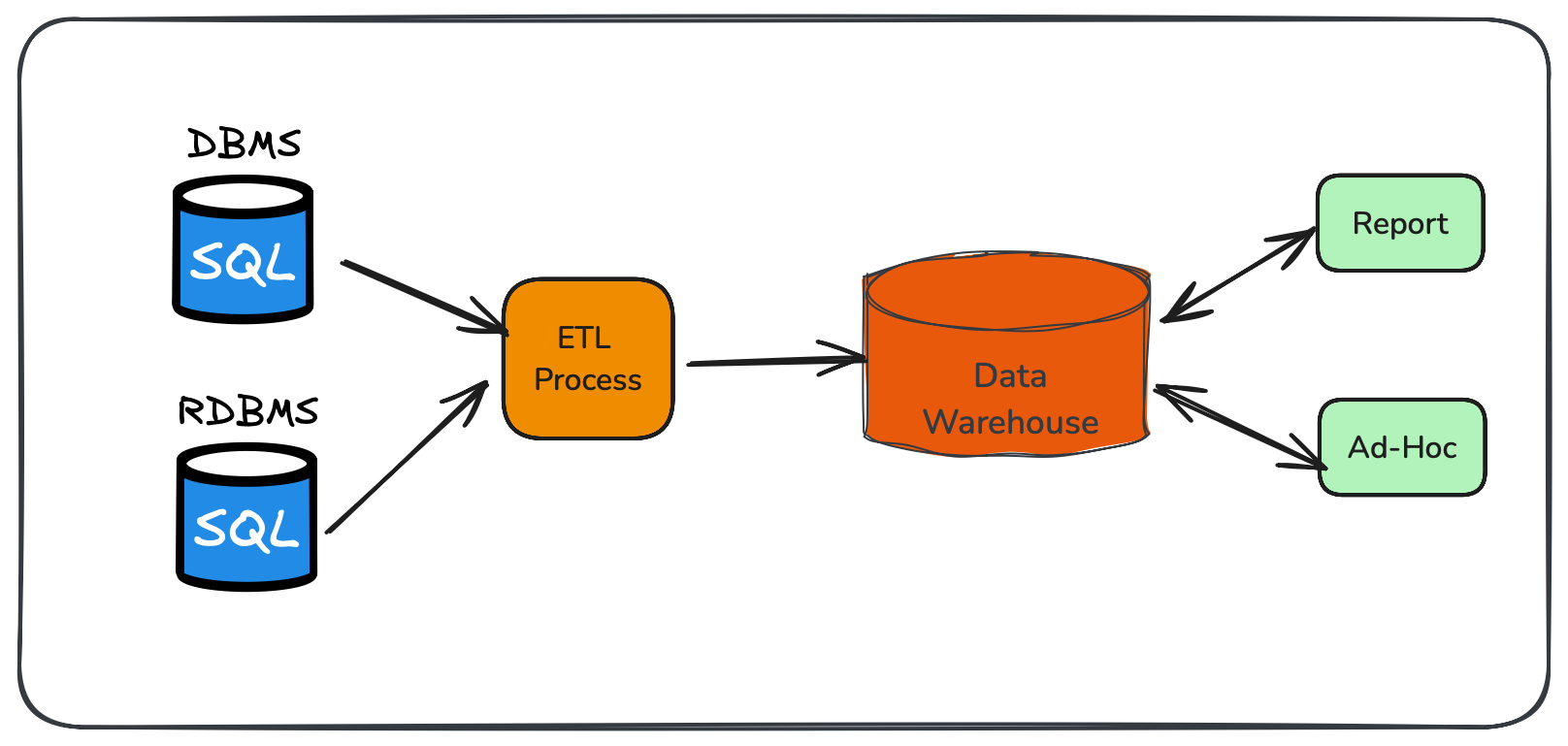
-
Lambda Architecture : 用两套系统,同时保证低延迟和结果准确
-
有状态的流式处理流程
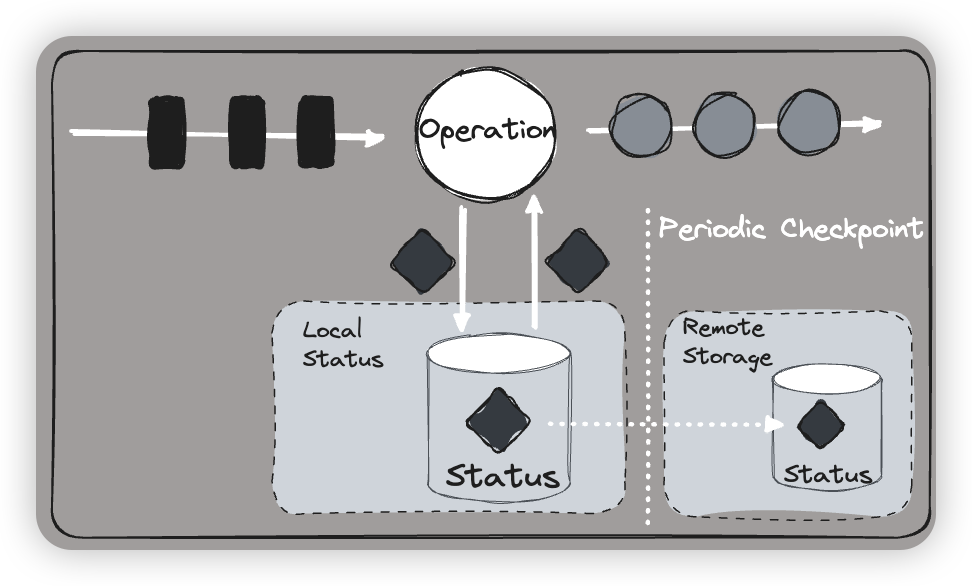
-
本质 : 事件驱动(Event-driven)
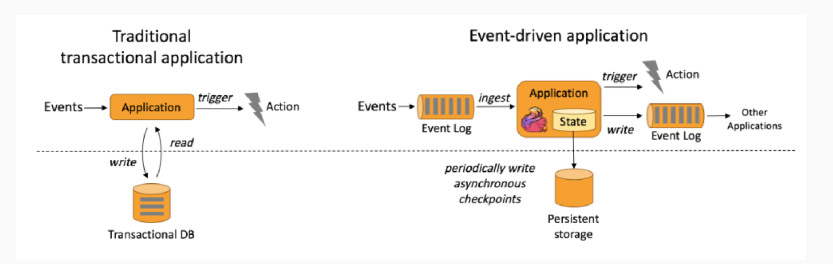
-
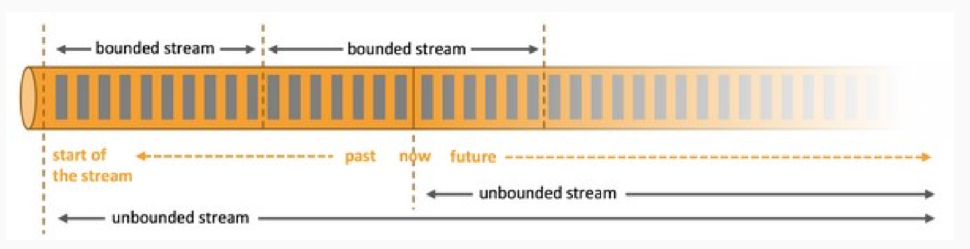
基于流的世界观 : 一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流:这就是所谓的有界流和无界流
-
Flink 分层API
-
有状态 与 无状态
Flink 组件栈
Deploy
- Local: Single JVM
- Cluster: YARN, Standalone
- Cloud: CE2, GE
Core
- Runtime: Distribute Streaming Dataflow
APIS & Libraries
- DataStream
- CEP(Event Perocessing)
- Table(Relational)
- Dataset
- FlinkML(Flink Machine Learning)
- Table(Relational)
- Gelly(Graphy Processing)
运行架构
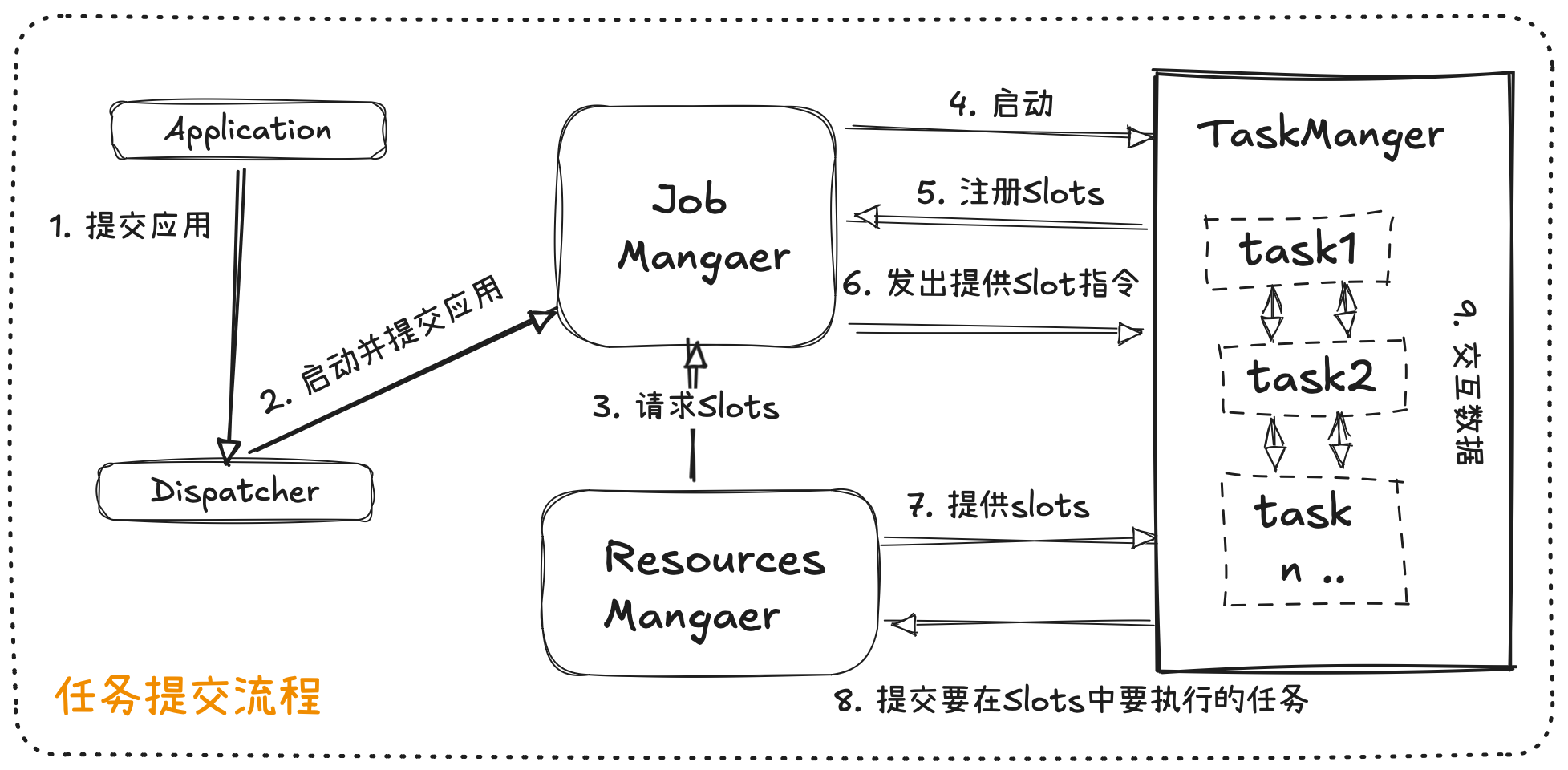
Flink 运行时的组件
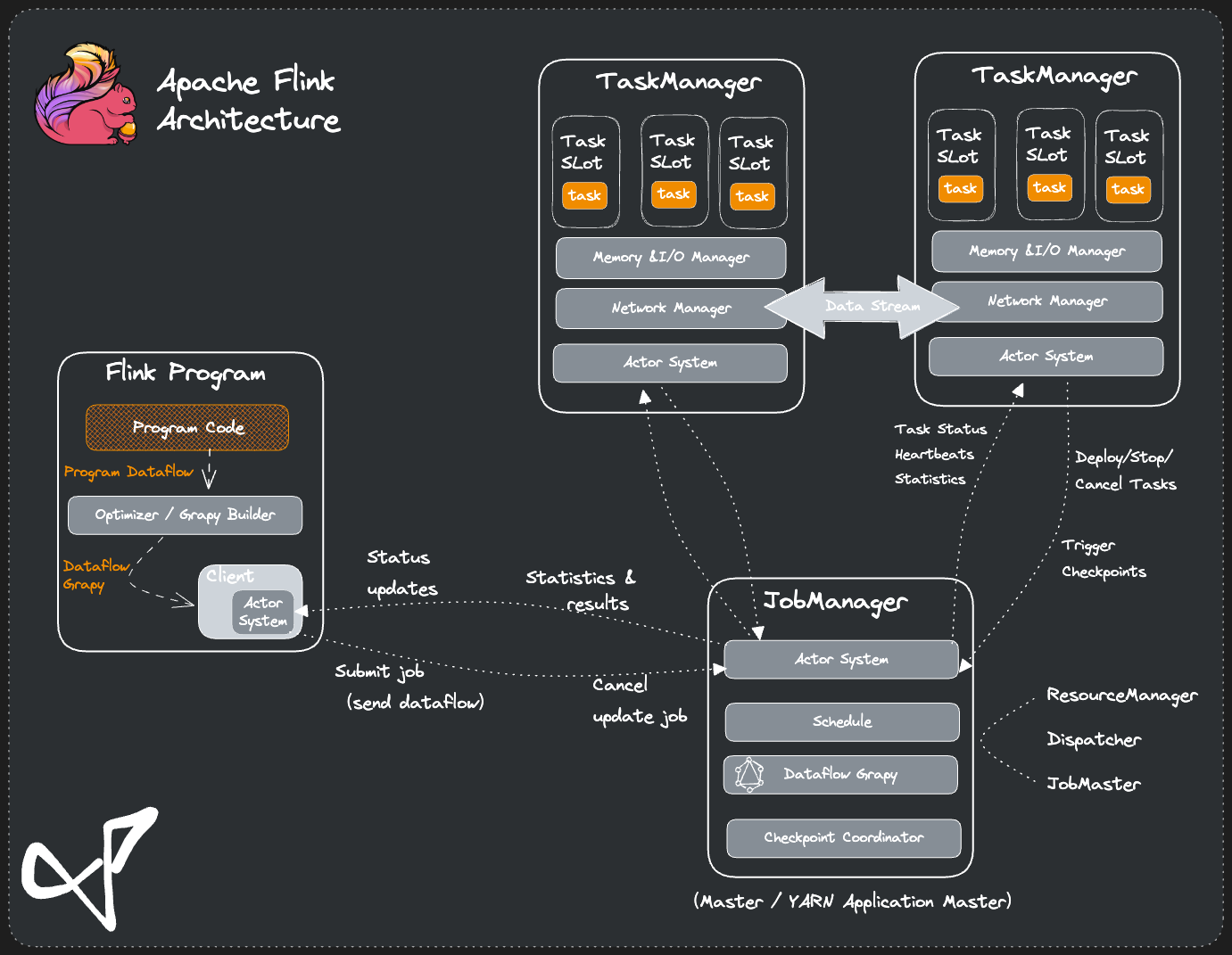
- 作业管理器 JobManager
- 资源管理器 ResourceManager
- 任务管理器 TaskManager
- 分发器 Dispatcher
数据流
- Source # 负责读取数据源
- Transformation # 利用各种算子进行处理加工
- Sink # 负责输出
网络IO通信底层
- erlang
- akka
- netty
典型的Master-Slave 架构
任务提交流程
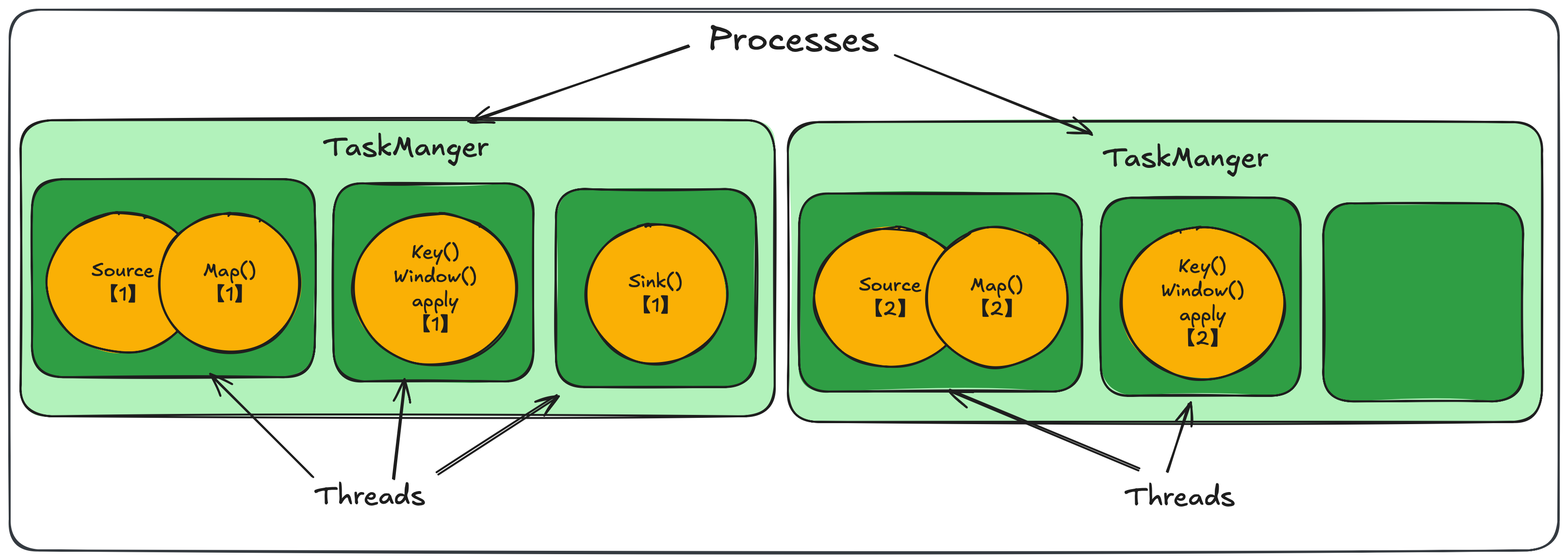
任务管理器和插槽
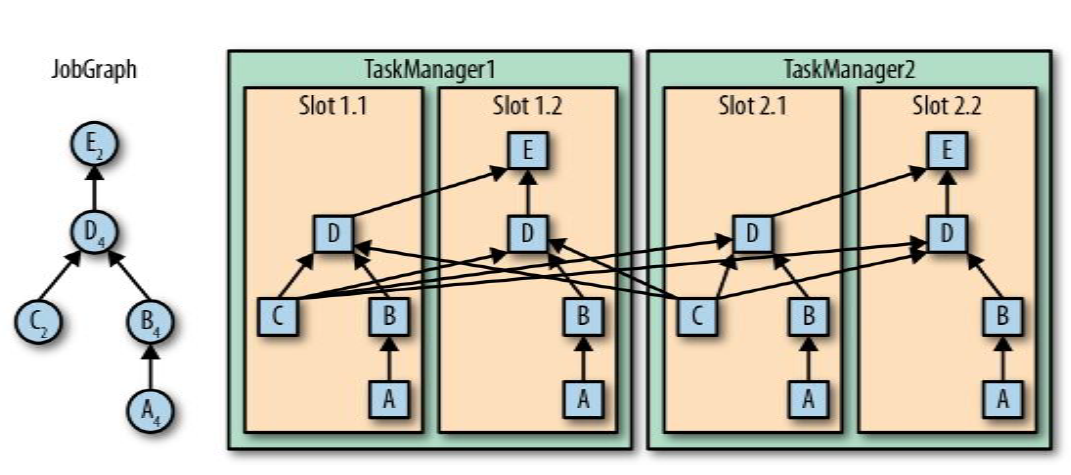
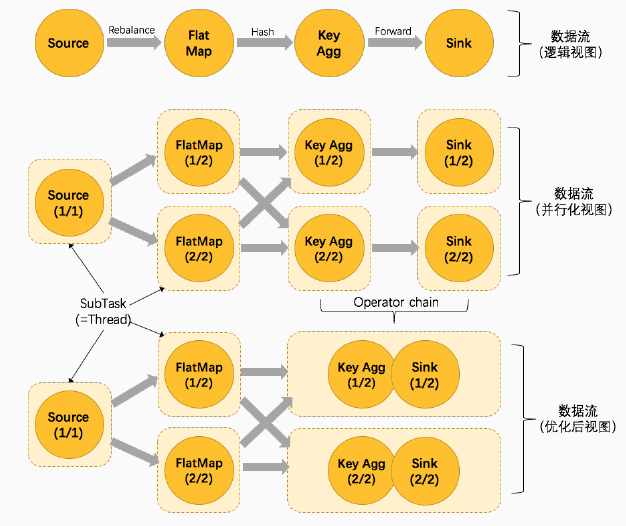
并行子任务分配
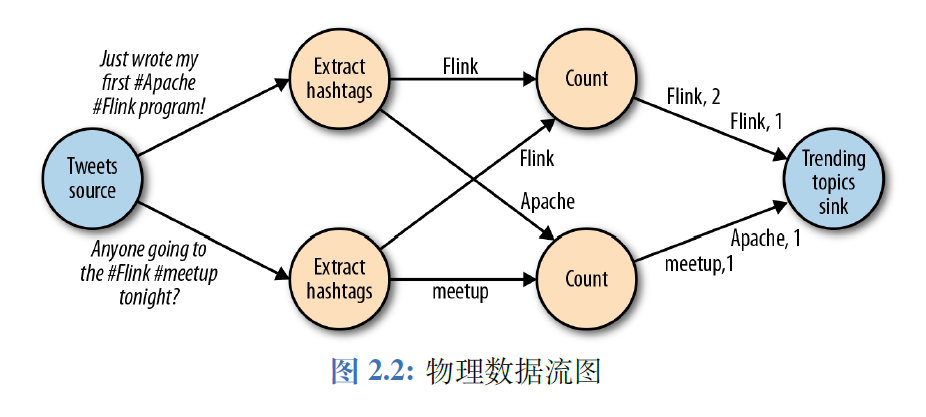
数据流

任务链
任务执行配置
Flink执行环境包括批处理和流处理两种情况,在1.12版本已经实现了流批的统一,默认执行模式为Streaming,可修改配置为Batch,在提交作业时候,设置的参数为:execution.runtime-mode
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar代码中实现的方式
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeMode.BATCH);DataSteam API
-
流处理 API
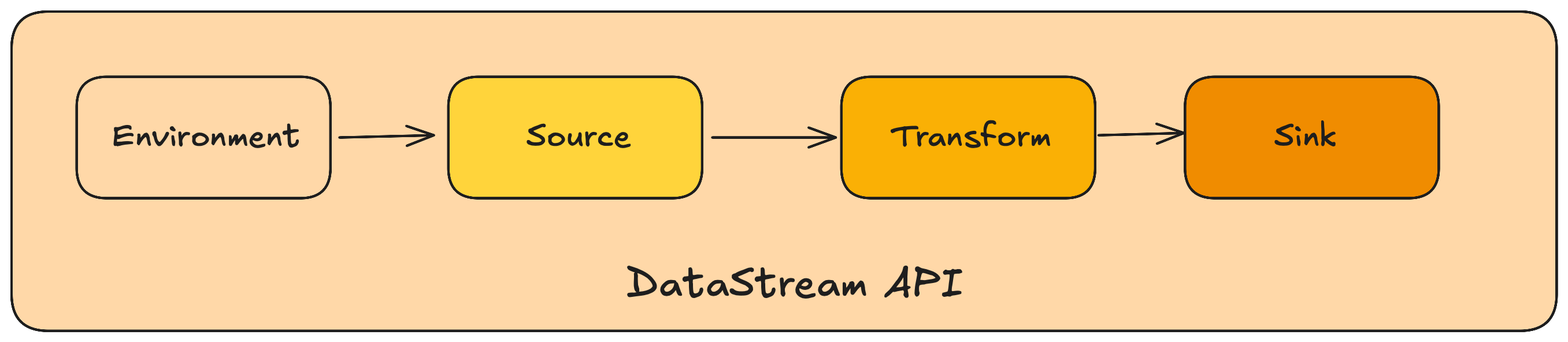
Flink中的算子是将’一个或多个DataStream’转换为’新的DataStream’,可以将多个转换组合成复杂的数据流拓扑。
- 源算子 Source # 数据读取,从集合. 文件. kafka. 自定义…
- 转换算子 Transformation
- 输出算子 Sink # 数据输出,写入文件. kafka. redis. Elasticsearch. JDBC…
Flink 的 Java DataStream API 可以将任何可序列化的对象转化为流。Flink 自带的序列化器有
基本类型,即 String、Long、Integer、Boolean、Array 复合类型:Tuples、POJOs
转换算子 Transformation
-
map # 理解为映射,对每个元素进行一定的变换后,映射为另一个元素。
-
flatmap # 理解为将元素摊平,每个元素可以变为0个. 1个. 或者多个元素。
-
filter # 进行筛选。
-
keyBy # 将Stream根据指定的Key进行分区,是根据key的散列值进行分区的。
-
滚动聚合算子( Rolling Aggregation ) : sum() min() max() minBy() maxBy()
-
reduce # 归并操作,它可以将KeyedStream 转变为 DataStream。
-
split 和 select # 将一个流拆分为多个流
-
connect 和 CoMap # 将两个流纵向地连接起来,数据类型可不同
-
union # 多个流合并到一个流中,以便对合并的流进行统一处理。是对多个流的水平拼接。参与合并的流必须是同一种类型。
-
fold # 给定一个初始值,将各个元素逐个归并计算。它将KeyedStream转变为DataStream。
-
join # 指定的Key将两个流进行关联。
map 和 flatMap 区别:
map:map方法返回的是一个object,map将流中的当前元素替换为此返回值;
flatMap:flatMap方法返回的是一个stream,flatMap将流中的当前元素替换为此返回流拆解的流元素;
例子 : 有二箱鸡蛋,每箱5个,现在要把鸡蛋加工成煎蛋,然后分给学生。
map做的事情:把二箱鸡蛋分别加工成煎蛋,还是放成原来的两箱,分给2组学生;
flatMap做的事情:把二箱鸡蛋分别加工成煎蛋,然后放到一起【10个煎蛋】,分给10个学生
基础数据类型
-
支持所有的 Java 和 Scala 基础数据类型, Int, Double, Long, String, …
-
Java 和 Scala 元组( Tuples )
-
Scala样例类( case classes )
-
Java简单对象( POJOs )
-
其它( Arrays, Lists, Maps , Enums, 等等)
实现 UDF 函数 更细粒度的控制流
-
函数类( Function Classes )
-
匿名函数( Lambda Functions )
-
富函数( Rich Functions ) # 可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
-
open()
-
getRuntimeContext().getState();
-
close()
Flink RichFunction & state
class flatMap_rich extends RichFlatMapFunction<In,Out>{
override def open(configuration:Confuration) : kic Unit = {}
//创建初始话函数,例如创建和外部系统的连接
override def flatMap(in : In,out:Collector<Out>)() :Unit = {}
//做一些操作
override def close : Unit = {}
//做一些清理工作,例如关闭和外部系统的连接
}-
DataStream

Window API
窗口(Window): [ ) 左闭右开 : 将无限流切割为有限流的一种方式,它会将流数据分发到有限大小的桶(bucket)中进行分析
窗口分类
-
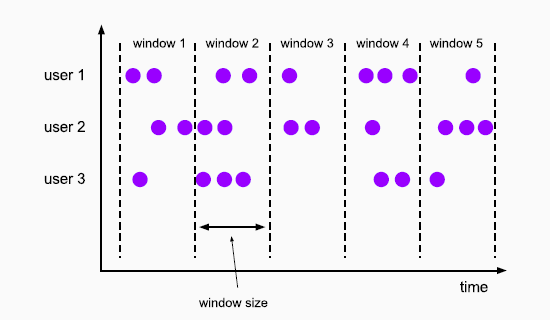
滚动窗口 Tumbling Windows
-
将数据依据固定的窗口长度对数据进行切分
-
时间对齐,窗口长度固定,没有重叠
-
-
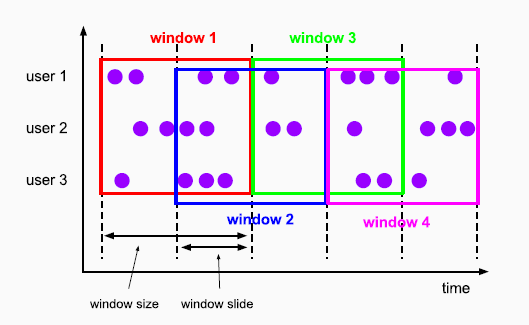
滑动窗口 Sliding Windows
-
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
-
窗口长度固定,可以有重叠
-
-
会话窗口 Session Windows
-
由一系列事件组合一个指定时间长度的timeout 间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口
-
时间无对齐
-
只有Flink 支持会话窗口
-
Wartermark
在Flink中,水位线(watermark)是一种’衡量Event Time进展’的机制,用来’处理实时数据中的乱序’问题的,通常是’水位线’和’窗口’结合使用来实现
- 水位线是一种逻辑时钟
- 水位线由程序员编程插入到数据流中
- 水位线是一种特殊的事件
- 在事件时间的世界里,水位线就是时间
- 水位线 = 观察到的最大时间戳 - 最大延迟时间 - 1 毫秒
- 水位线超过窗口结束时间,窗口闭合,默认情况下,迟到元素被抛弃
- Flink 会在流的最开始插入一个时间戳为负无穷大的水位线
- Flink 会在流的最末尾插入一个时间戳为正无穷大的水位线
- Event Time(事件时间):事件创建的时间(必须包含在数据源中的元素里面)
- Ingestion Time(摄入时间):数据进入Flink 的source 算子的时间,与机器相关
- Processing Time(处理时间):执行操作算子的本地系统时间,与机器相关
迟到数据处理的原因 : 由于网络. 分布式等原因,会导致乱序数据的产生
1. 直接抛弃迟到的元素
2. 将迟到的元素发送到另一条流中去
3. 可以更新窗口已经计算完的结果,并发出计算结果
状态管理
Flink 中的状态 # 类似本地变量
- 算子状态 Operatior State # 算子状态的作用范围限定为算子任务
- 列表状态 List state
- 联合列表状态 Union list state
- 广播状态 Broadcast state
- 键控状态 Keyed State # 根据输入数据流中定义的键( key )来维护和 访问
- 值状态(ValueState):将状态表示为单个的值
- 列表状态(List State):将状态表示为一组数据的列表
- 字典状态(MapState):将状态表示为一组Key-Value 对
- 聚合状态:将状态表示为一个用于聚合操作的列表
- 状态后端 State Backends # 状态的存储 . 访问以及维护
容错机制
- Flink 故障恢复机制的核心 : 应用状态的一致性检查点
- 应用状态的一致性检查点 : 所有任务的状态,在某个时间点的一份的快照 ( 时间点 : 是所有任务都恰好处理完一个相同的输入数据的时候)
- 从检查点恢复状态
- 重启应用
- 从 checkpoint 中读取状态,将状态重置
- 开始消费并处理检查点到发生故障之间的所有数据 # 精确一次
状态一致性
状态一致性分类
- AT-MOST-ONCE(最多一次) - 当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据。At-most-once 语义的含义是最多处理一次事件。例如:UDP,不提供任何一致性保障
- AT-LEAST-ONCE(至少一次) - 在大多数的真实应用场景,我们希望不丢失事件。这种类型的保障称为at-least-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次。
- EXACTLY-ONCE(精确一次) - 恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
- 内部保证——checkpoint(分布式异步快照算法)
- Source 端——可重设数据的读取位置(Kafka,FileSystem)
- Sink 端——从故障恢复时,数据不会重复写入外部系统 幂等写入:是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了 事务写入:应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消(ACID);具有原子性:一个事务中的一系列的操作要么全部成功,要么一个都不做