 Apache ZooKeeper™ is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Apache ZooKeeper™ is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
下文以“ZK”称呼
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
- ZK 致力于开发和维护开源服务器,以实现高度可靠的分布式协调
- 发布/订阅模式的分布式数据管理与协调框架
ZK是Apache开源提供的一个分布式协调服务框架,主要用来解决分布式集群中应用系统的一致性问题,例如怎样避免同时操作同一数据造成脏读的问题。ZK 本质上是一个分布式的小文件存储系统。提供基于类似于文件系 统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维 护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达 到基于数据的集群管理。 诸如: 统一命名服务(dubbo)、分布式配置管理(solr的配置集中管理)、分布式消息队列(sub/pub)、分布式锁、分布式协调等功能。
zk当中的基本特性
- 全局数据一致性:所有的节点,看到的数据都是一模一样的
- 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;偏序是指如果一个消息 b 在消息 a 后被同一个发送者发布, a 必将排在 b 前面
- 数据更新的原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态
- 实时性:在一段时间之内,zk当中的消息,必定会送达每一个节点
架构
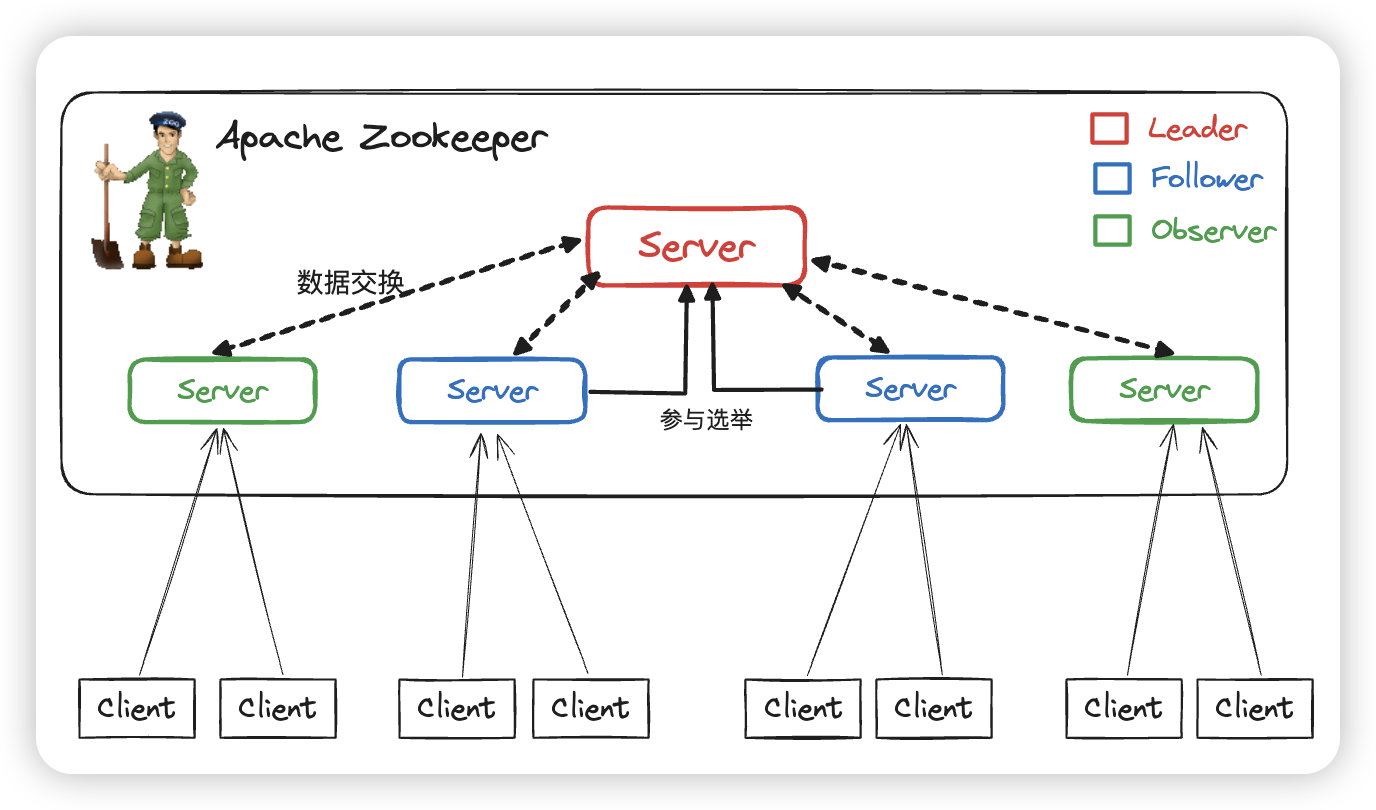
Leader
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性
- 集群内部各服务的调度者
- 管理投票工作 🗳️
如果leader死掉了之后,zk会冲洗投票选举,从follower当中重新选举一个主节点出来
Follower
- 处理客户端的非事务请求(读操作),转发事务(写请求)请求给Leader服务器
- 参与Leader选举投票
Observer
- 处理客户端的非事务请求,转发事务请求给Leader服务器
- 不参与任何形式的投票
- 3.3.0版本以后引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
Client
- 都保存同一份相同的数据副本,区别在于该请求是处理事物的还是非事物的
服务器工作状态
- LOOKING:寻找Leader状态。当服务器处于该状态时,它会认为当前集群中没有Leader,因此需要进入Leader选举状态
- FOLLOWING:跟随者状态。表明当前服务器角色是Follower
- LEADING:领导者状态。表明当前服务器角色是Leader
- OBSERVING:观察者状态。表明当前服务器角色是Observer
选举机制
ZK的默认的选举算法是FastLeaderElection,即投票过半则胜出
参选指标
- 服务器ID:被推举的Leader的SID
- 数据ID(zxid):被推举的Leader事务ID
- 逻辑时钟(electionEpoch):逻辑时钟,用来判断多个投票是否在同一轮选举周期中,该值在服务端是一个自增序列,每次进入新一轮的投票后,都会对该值进行加1操作
启动时选举
集群Down机后选举
数据模型
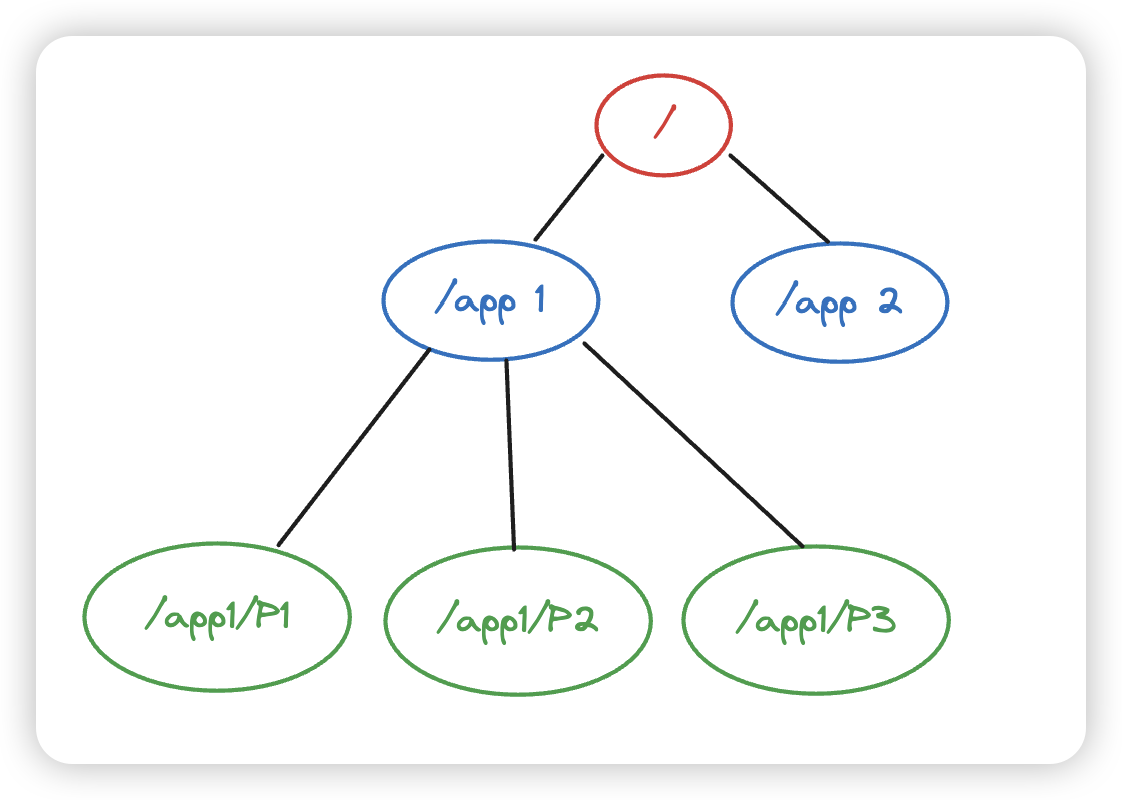 采用的是树形的结构,每一个节点,称之为一个znode,每一个znode兼具有文件和文件夹的特性
采用的是树形的结构,每一个节点,称之为一个znode,每一个znode兼具有文件和文件夹的特性
- 文件:可以存储数据
- 文件夹:下面可以有子文件或者子文件夹
Warning
- znode存储的数据的大小有限制,不超过1M。小文件存储系统
- znode的访问,必须使用绝对路径 /开头的路径
znode的类型
永久节点
- 普通的永久节点
- 序列化的永久节点
临时节点
- 普通的临时节点
- 序列化的临时节点
应用场景
- 数据发布/订阅
- 负载均衡
- 命名服务
- 分布式协调/通知
- 集群管理
- Master选举
- 分布式锁
- 分布式队列
ZK与CP
ZK遵循的是CP原则,即一致性和分区容错性,牺牲了可用性
- 当Leader宕机以后,集群机器马上会进去到新的Leader选举中,但是选举时长在30s — 120s之间,这个选取Leader期间,是不提供服务的,不满足可用性,所以牺牲了可用性
部署模式
集群规则为2N+1台,N>0,即3台
- 单机模式
- 伪集群模式
- 集群模式
启动zookeeper服务
#!/bin/bash
case $1 in
"start"){
for i in bigdata101 bigdata102 bigdata103
do
echo "------------- $i -------------"
ssh $i "/opt/apps/zookeeper/bin/zkServer.sh start"
done
};;
"stop"){
for i in bigdata101 bigdata102 bigdata103
do
echo "------------- $i -------------"
ssh $i "/opt/apps/zookeeper/bin/zkServer.sh stop"
done
};;
"status"){
for i in bigdata101 bigdata102 bigdata103
do
echo "------------- $i -------------"
ssh $i "/opt/apps/zookeeper/bin/zkServer.sh status"
done
};;
esac