What is HBase?
HBase is a non-relational, distributed database modeled after Google's Bigtable. It provides random, real-time read/write access to large datasets - billions of rows with millions of columns - atop clusters of commodity hardware. Unlike traditional relational databases, HBase is designed for wide tables and prioritizes scalability over features like SQL support, typed columns, or advanced query languages.
Hbase(Hadoop on database)是基于hdfs进行数据的存储,具有高可靠. 高性能. 列存储. 可伸缩. 实时读写的nosql数据库。它可以存储海量数据,并且后期查询性能很多,可以实现上亿条数据的秒级返回。
Key characteristics of HBase include:
- Strongly consistent reads/writes: HBase is not an “eventually consistent” data store
- Automatic sharding: Tables are distributed across the cluster via regions
- Automatic failover: Built-in support for RegionServer failure recovery
- Hadoop/HDFS integration: Native support for HDFS as its distributed file system
- Linear scalability: Add more RegionServers to increase capacity
- Block cache and Bloom filters: Optimizations for high-volume query performance
When to Use HBase:
HBase is most suitable when:
- You have hundreds of millions or billions of rows
- You can work without RDBMS features like typed columns, secondary indexes, transactions, and SQL
- You have enough hardware (at least 5 DataNodes for a proper HDFS cluster)
- You need random, real-time read/write access to your Big Data For smaller datasets (thousands/millions of rows), a traditional RDBMS might be a better choice.
场景:
- 可利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群
- HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据
HBase 特性
- 大:hbase表可以存储海量数据。Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据
- 无模式
- mysql表中每一行数据他 们的字段都是一样
- hbase表中不同的行可以有不同的列(字段)
- 面向列
- mysql表中的数据是基于行进行存储,把每一行数据写入到磁盘文件中
- hbase表中的数据是基于列进行存储,把相同列的数据写入到磁盘文件中、
- 列式存储其实说的是列族(Column Family)存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定
- 稀疏:hbase表中为null的列,不占用实际的存储空间
- 数据的多版本:hbase表中的数据在进行更新操作的时候,并没有直接把原始数据删除掉,而是保留数据的多个版本,这个数据的版本号就是按照数据插入时的时间戳去确定
- 数据类型单一:无论你的数据是什么,在hbase表中统一使用字节数组进行存储
- 极易扩展:Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS) 。通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力
- 高并发(多核):由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务
Hbase的内部原理
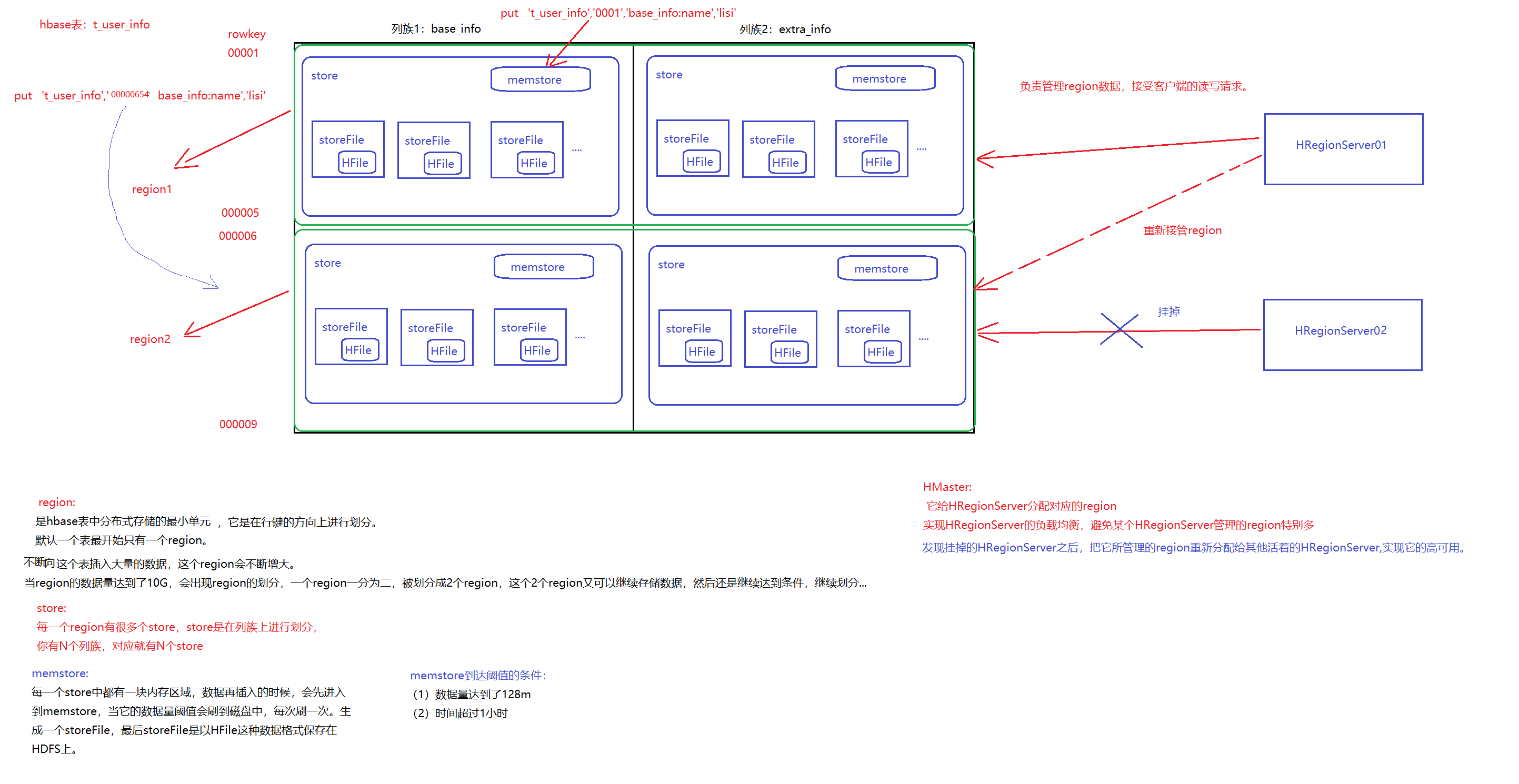
Hbase的寻址机制
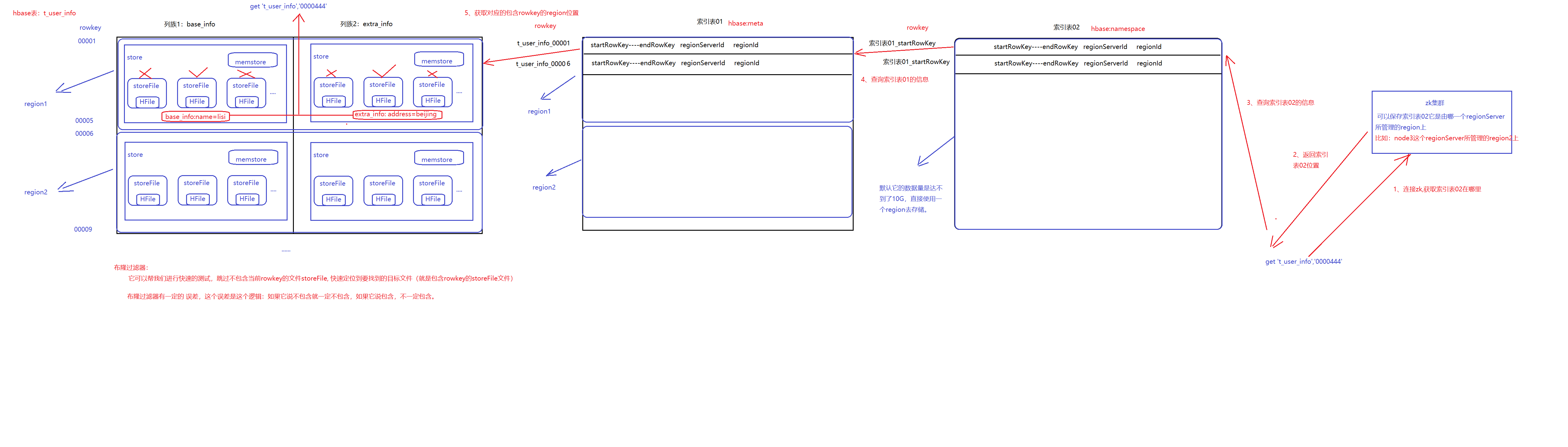
HBase架构

Hbase是由Client、Zookeeper、Master、HRegionServer、HDFS等几个组件组成,几个组件的相关功能:
- Client
- Client包含了访问Hbase的接口,另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息。
- Zookeeper
- HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务、通过Zoopkeeper来监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知Master RegionServer上下线的信息、通过Zoopkeeper存储元数据的统一入口地址。
- Hmaster(NameNode) 节点的主要职责如下: 为RegionServer分配Region、维护整个集群的负载均衡、维护集群的元数据信息、发现失效的Region,并将失效的Region分配到正常的RegionServer上、当RegionSever失效的时候,协调对应Hlog的拆分。
- HregionServer(DataNode) :直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下: 管理master为其分配的Region、处理来自客户端的读写请求、负责和底层HDFS的交互,存储数据到HDFS、负责Region变大以后的拆分、负责Storefile的合并工作。
- HDFS:为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:提供元数据和表数据的底层分布式存储服务、数据多副本,保证的高可靠和高可用性。
- 其他组件
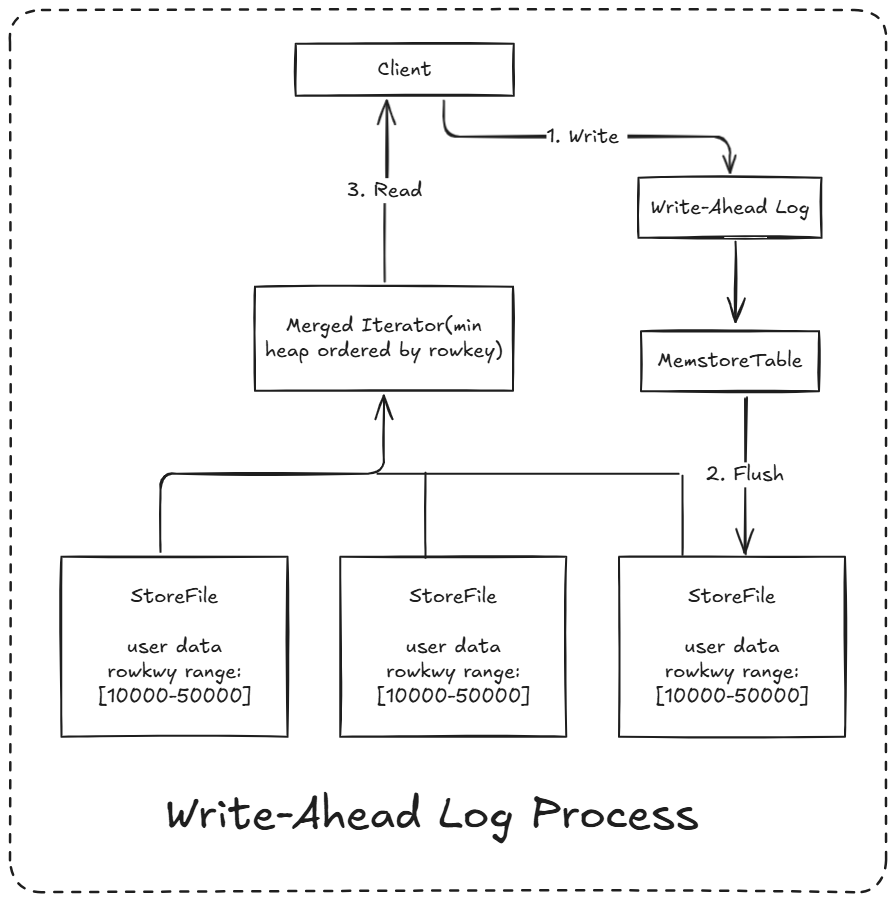
- Write-Ahead logs: HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建
- Region:Hbase表的分片,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
- Store:HFile存储在Store中,一个Store对应HBase表中的一个列族(列簇, Column Family)。
- MemStore:顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
- HFile:这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile是以Hfile的形式存储在HDFS的。
HBase原理
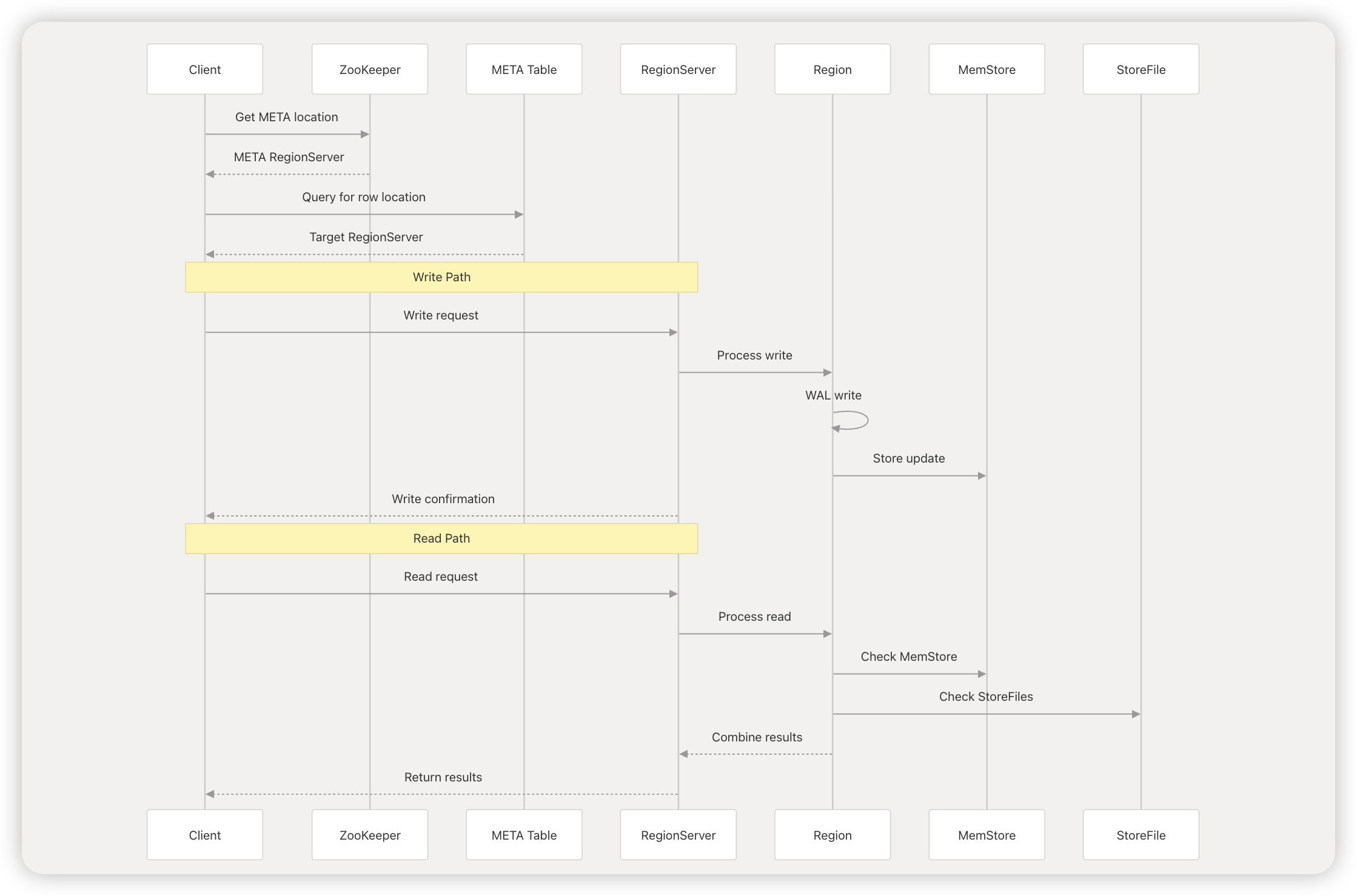
HBase读流程
- Client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息
- 根据namespace、表名和rowkey在meta表中找到对应的region信息
- 找到这个region对应的regionserver
- 查找对应的region
- 先从MemStore找数据,如果没有,再到BlockCache里面读
- BlockCache还没有,再到StoreFile上读(为了读取的效率)
- 如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端
HBase写流程
- Client向HregionServer发送写请求
- HregionServer将数据写到HLog(write ahead log)。为了数据的持久化和恢复
- HregionServer将数据写到内存(MemStore)
- 反馈Client写成功
数据flush过程
- 当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据
- 并将数据存储到HDFS中
- 在HLog中做标记点
数据合并过程
- 当数据块达到3块,Hmaster触发合并操作,Region将数据块加载到本地,进行合并
- 当合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HregionServer管理
- 当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META
HLog会同步到HDFS
Data Model
graph TD A["Table"] B["Region 1"] C["Region 2"] D["Region N"] E["Column Family 1"] F["Column Family 2"] G["Cells(Key-Value Pairs)"] H["Cells(Key-Value Pairs)"] I["(row,column,timestamp) → value"] A --> B A --> C A --> D B --> E E --> G G --> I B --> F F --> H
Hbase Shell
# 查看hbase状态
status
1、启动命令 # /usr/lib/hbase/bin
hbase shell
################################# 表空间 namespace
2、查看当前Hbase中所有的namespace
list_namespace
3、创建 namespace 并附带表空间属性
create_namespace "test"
create_namespace "test01", {"author"=>"zhj", "create_time"=>"2020-03-10 08:08:08"}
4、查看 namespace
describe_namespace "test01"
5、修改 namespace 的属性值(添加或者修改属性)
alter_namespace "test01", {METHOD => 'set', 'author' => 'wxy'} # 修改
alter_namespace "test01", {METHOD => 'set', 'year' => '2019'} # 新增
5-1、删除 namespace 的属性
alter_namespace 'test01', {METHOD => 'unset', NAME => 'create_time'} # 删除
6、删除 namespace
drop_namespace "test01" # 要删除的namespace必须是空的,其下没有表
################################# 表 table [ 表空间:表名 ] [ namespace:table ]
DDL
0、查看表空间有哪些表
list # 显示所有表
list_namespace_tables 'test' # 显示指定表空间里的表
1、创建表
create 'student','info' # 指定默认表空间 default ; 'info' 为列族
create 'stu1',{NAME=>'col1'},{NAME=>'col2'} # 指定默认表空间,多个列族col1,col2
# create 'stu2','col1','col2' # 简便写法
create 'test:student','info' # 指定表空间为test ; 'info' 为列族
1-1、修改表信息
alter 'student',NAME=>'info_2',VERSIONS=>'2' # 新增/修改表的列族 ,保留版本的个数为2
# 默认 VERSIONS 为1 , 存储历史几个版本 , 如果有数据写入,那么较老的时间戳的数据会忽略作废。
alter 'student','delete'=>'info_2' # 删除表的列族
alter 'emp', READONLY # 修改表为只读
2、删除表 # 删除表的操作顺序为先disable,然后再drop
disable 'student' # 修改表为disable状态
drop 'student' # 删除表
3、查看表结构
describe 'test:student' # 查看表信息 简写 : desc
DML
1、向表添加数据 # put '表空间:表','rowkey','列族:列名','value' rowkey 会自动排序
put 'student','1001','info:sex','male' # 列族下的列名sex
put 'student','1001','info:age','18'
put 'student','1002','info:name','Janna'
put 'student','1002','info:sex','female'
put 'student','1002','info:age','20'
2、扫描查看表数据 # STARTROW -> STOPROW 排序按照:ASCII
scan 'student'
scan 'student',{RAW=>true,VERSIONS=>2} # 追加显示多版本数据
scan 'student',{STARTROW => '1001', STOPROW => '1001'} # 查看rowkey为1001
# scan 'student',{STARTROW => '1001', STOPROW => '1005!'} # 查看rowkey为1005
# scan 'student',{STARTROW => '1001', STOPROW => '1005|'} # 查看rowkey为1005?
scan 'student',{STARTROW => '1001'} # 1001开始
3、更新指定字段的数据
put 'student','1001','info:name','Nick'
put 'student','1001','info:age','100'
4、查看“指定行”或“指定列族:列”的数据
get 'student','1001'
get 'student','1001','info:name'
get 'student','1001','info:name','info:age'
5、统计表数据行数
count 'student'
6、删除数据
deleteall 'student','1001' # 删除rowkey都为1001 DeletColumn 列 DeleteFamily 列族
delete 'student','1001','info:age' # 删除rowkey为1001列族为info列名为sex的所有版本信息
7、清空表 # 清空表的操作顺序为先disable,然后再truncate
disable 'student' # 修改表为disable状态
truncate 'student'
+++ HBase Shell 执行命令
./hbase shell /zhj/sample_commands.txt # habse shell 调用txt脚本Hbase API
pom.xml // maven 依赖
<repositories>
<repository>
<id>cloudera</id> // 指定仓库地址
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.7.0</version> // 选择cdh版本
// <version>2.0.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.7.0</version> // // 选择cdh版本
// <version>2.0.5</version>
</dependency>
</dependencies>
++++++++++++++++++++++++++++++++
hbase-site.xml //hbase-site.xml 配置文件参数
<property>
<name>hbase.zookeeper.quorum</name> // API Connection 参数1
<value>quickstart.cloudera</value> // API Connection 参数2
</property>
++++++++++++++++++++++++++++++++
* Connection : 通过ConnectionFactory获取. 是重量级实现.
private static Connection connection ; // 定义连接
Configuration conf = HBaseConfiguration.create(); // 创建配置信息并配置
conf.set("hbase.zookeeper.quorum","quickstart.cloudera");
connection = ConnectionFactory.createConnection(conf); // 创建连接
Admin admin = connection.getAdmin(); // 创建操作对象
admin.close(); // 关闭对象连接
connection.close(); // 关闭对象连接
* Table : 主要负责DML操作
* Admin : 主要负责DDL操作
DDL // 创建NameSpace、创建table、删除table
1、判断表是否存在
boolean exists = admin.tableExists(TableName.valueOf("test:stu"));
2、 创建表
3、 删除表
TableName name = TableName.valueOf("test:stu1");
admin.disableTable(name); //表下线
admin.deleteTable(name); //表删除
4、 创建命名空间
DML // put 、delete 、get 、scan
1、插入数据
2、单条数据查询
3、扫描数据
4、删除数据Hbase 优化
预分区
每一个region维护着 'Start key' 与 'End Key' # 排序按照:ASCII
1、手动设置预分区 # 建表时候设定预分区
create 'staff1','info',SPLITS => ['1000','2000','3000','4000']
# (-∞,1000),[1000,2000),[2000,3000),[3000,4000),[4000,+∞)
2、生成16进制序列预分区
create 'staff2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
# 00000000-fffffff
3、按照文件中设置的规则预分区 # 文件使用相对路径,或者绝对路径
create 'staff3','info',SPLITS_FILE => 'splits.txt'
# aaaa
# bbbb
# cccc
# dddd
4、使用JavaAPI创建预分区![]()
Summary
Hbase is a distributed NoSQL database built on Hadoop that provides random, real-time read/write access to large datasets. Its architecture consists of a Master server for cluster management, RegionServers for data operations, ZooKeeper for coordination, and HDFS for storage. The system is designed for horizontal scalability and fault tolerance while offering multiple client interfaces for integration with various applications.