mindmap root((Apache Hive)) Hive Architecture Hive Metastore Server (HMS) Hive Develop Doc Hive Deploy Documentation
Apache Hive
Hive由Facebook开源,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类
SQL查询功能,解决海量结构化日志的数据统计工具
Hive本质:将HQL转化成 MapReduce 程序
- hive处理的数据存在HDFS
- hive默认分析计算引擎是MapReduce
- hive执行程序运行在Hadoop Yarn
Hive Architecture
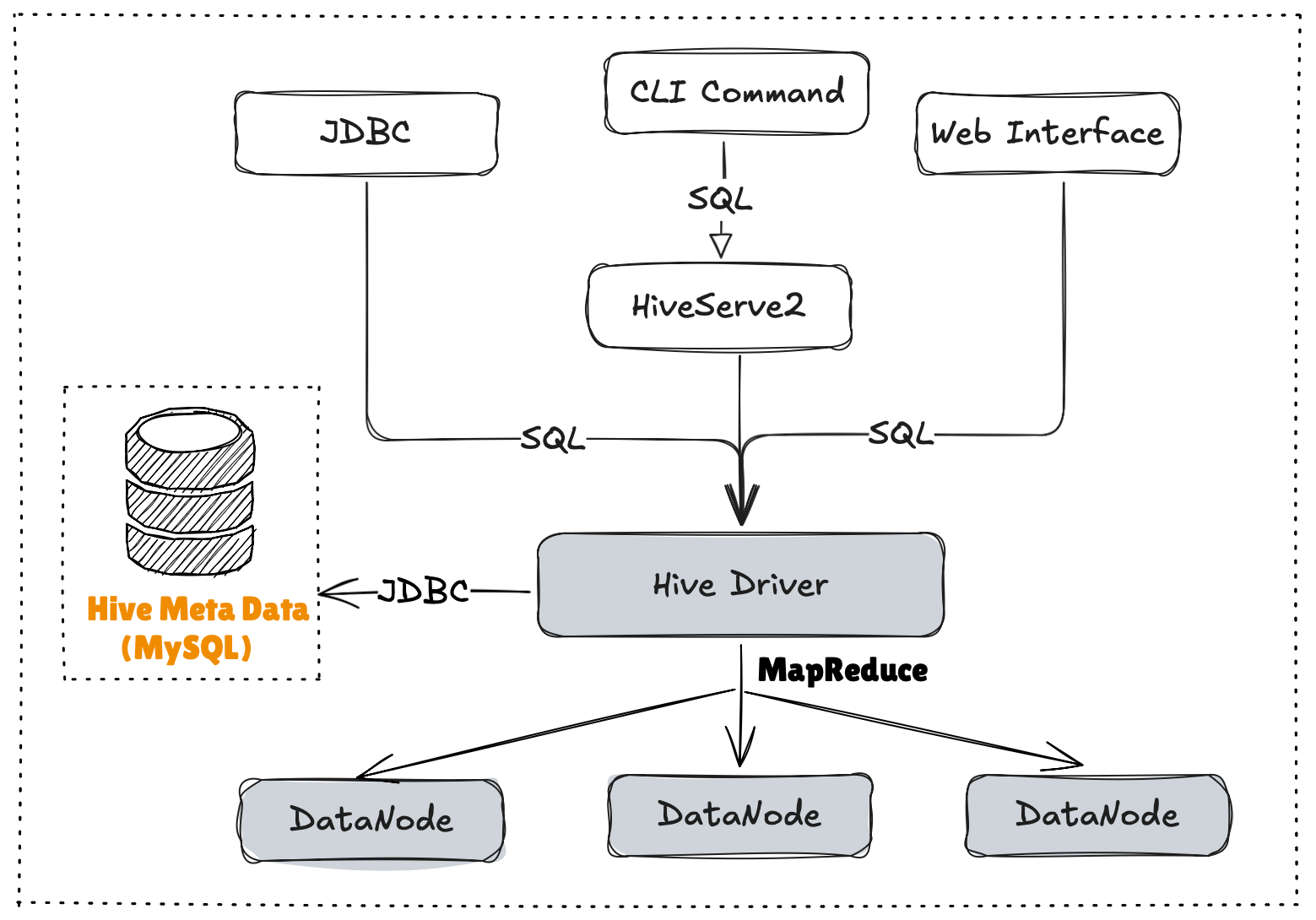
- 用户接口:Client
- CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
- 元数据:Metastore
- 默认存储在自带的
derby数据库中,推荐使用MySQL存储Metastore(表名,表的列,库信息)
- 默认存储在自带的
- Hadoop
- 使用HDFS进行存储,使用MapReduce进行计算
- 路径: /user/hive/warehouse
- 驱动器:Driver
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误
- 编译器(Physical Plan):将AST编译生成逻辑执行计划
- 优化器(Query Optimizer):对逻辑执行计划进行优化
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark
Hive Metastore Server (HMS)
Hive是针对数据仓库应用设计的,而数据仓库的内容是
读多写少的。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的
Hive的数据模型
| Hive | HDFS |
|---|---|
| 表 | 目录 |
| 分区 | 目录 |
| 数据 | 文件 |
| 桶 | 文件 |
| 视图 | / |
Hive Relateion
Hive Integration
- Hive on Spark: Getting Started
- Hive HBase Integration
- Druid Integration
- Kudu Integration Streaming Data Ingest, and Streaming Mutation API
- Hive Counters
- Using TiDB as the Hive Metastore database
- StarRocks Integration
- Hive Accumulo Integration
- Hive Transactions,
Hive On Cloud
- Hive on Aliyun JMR
- Hive on JDCLoud JMR
- Hive on Amazon Web Services
Resources
- Hive Tutorial
- Hive SQL Language Manual: Commands, CLIs, Data Types,
DDL (create/drop/alter/truncate/show/describe), Statistics (analyze), Indexes, Archiving,
DML (load/insert/update/delete/merge, import/export, explain plan),
Queries (select), Operators and UDFs, Locks, Authorization - File Formats and Compression: RCFile, Avro, ORC, Parquet; Compression, LZO
- Procedural Language: Hive HPL/SQL
- Hive Configuration Properties
- Hive Clients
- Hive Client (JDBC, ODBC, Thrift)
- HiveServer2: Overview, HiveServer2 Client and Beeline, Hive Metrics
- Hive Web Interface
- Hive SerDes: Avro SerDe, Parquet SerDe, CSV SerDe, JSON SerDe