定义
Kafka 由Scala和Java编写,Kafka是一种高吞吐量的分布式发布-订阅消息系统,默认端口: 9092:
-
消息队列(mq): 消息的传输过程中保存消息的容器 , 把要传输的数据放在队列中 -
发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息
Version
| 版本 | 核心亮点 |
|---|---|
| 3.0 | 强化交付保障,升级 ZooKeeper |
| 3.6 | Tiered Storage 支持 |
| 3.7 | MSK 支持 KRaft,多 broker 扩展 |
| 3.8 | 压缩级别配置、JBOD、预览 rebalance 协议 |
| 3.9 | 动态 KRaft quorum,淘汰 ZooKeeper |
| 4.0 | 完全 KRaft,Queue 模式,rebalance 协议完善,多项现代化更新 |
API
Kafka拥有三个非常重要的角色特性
- 消息系统:与传统的消息队列或者消息系统类似
- 存储系统:可以把消息持久化到磁盘,有较好的容错性
- 流式处理平台:可以在流式记录产生时就进行处理
消息队列的两种模式
两种类型的消息传递模式可用:
- 点、对点模式(一对一) : 一个生产者+一个消费者+一个topic,会删除数据
不常用。消费者主动拉取数据,消息收到后清除消息 - 发布-订阅模式(多对多) : 多个生产者+多个消费者+多个topic/相互独立,不会删除数据
基础架构
Kafka支持的主要应用场景
- 削峰填谷:所谓的“削峰填谷”就是指缓冲上下游瞬时突发流量,使其更平滑
- 解耦 :即允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束
- 异步通信:即允许把一个消息放入队列,但并不立即处理它们,然后再需要的时候才去处理它们。
总体模块划分(server 侧)
kafka/
├─ server/ # Broker 主流程:网络、协议分发、Replica 管理、协调器等
├─ storage/ # 日志存储:Log/Segment/Index/records 压缩与保留
├─ raft/ # KRaft 实现:Raft 日志、投票、快照、Controller
├─ controller/ # 元数据控制器(KRaft),分区/副本状态机
├─ zookeeper/ # 兼容旧架构(如仍使用 ZK)
├─ network/ # SocketServer/Reactor/Selector/Quota
├─ coordinator/ # GroupCoordinator/TxnCoordinator(消费组与事务)
├─ common/clients/ # 通用协议、Record 格式、压缩等(客户端与服务端共用)
└─ tools/ # 维护工具启动与主循环
Broker 启动
- 入口:
kafka.Kafka(main)→KafkaServer - 核心步骤:加载配置 → 日志目录检查 → 网络层
SocketServer启动 →ReplicaManager启动 → 协调器(Group/Txn)→ 控制器客户端(ZK 或 KRaft)初始化 → 接受请求。
网络与请求分发
- 关键类
SocketServer/KafkaRequestHandlerPoolProcessor(NIO 线程)+RequestChannelKafkaApis:协议分发中心(handleProduce/handleFetch/handleJoinGroup/…)
- 要点
- Reactor 模型:Acceptor → 多个 Processor(Selector)→ 请求队列 → 多个 Handler 线程执行业务。
- 零拷贝:发送
.log文件时可使用transferTo
存储子系统(Log)
数据结构
- Log/LogSegment
Log: 分区在磁盘的抽象;包含多个LogSegmentLogSegment: 三元组文件.log(RecordBatch 流).index(offset → 文件位置稀疏索引).timeindex(timestamp → 文件位置)
- Record & RecordBatch
- 批为单位(压缩/CRC/魔数),含
baseOffset、producerId/epoch/sequence(用于幂等/事务)
- 批为单位(压缩/CRC/魔数),含
- Offset 边界
- LEO(log end offset)
- HW(high watermark,同步副本可见的最高 offset)
写入路径(Produce)
KafkaApis.handleProduce
→ ReplicaManager.appendRecords()
→ Partition.appendRecordsToLeader()
→ Log.append()
→ 当前 segment 追加(可能 roll)
→ 更新 LEO/索引/时间索引
→ 等待副本复制达成acks条件(ISR 达到 → 提升 HW)
读取路径(Fetch)
KafkaApis.handleFetch
→ ReplicaManager.fetchMessages()
→ Partition.readRecords()
→ Log.read()
→ 索引定位(offset/time),从 .log 顺序读(可能零拷贝)
→ 返回 RecordBatch(可带压缩)维护任务
- 保留与清理
- 基于时间/大小的保留:
log.cleaner/log.retention.* - Log Compaction:按 key 保留“最新值”(
LogCleaner后台线程:从源 segment 合并成新的 compacted 段)
- 基于时间/大小的保留:
- Segment 滚动
- 触发条件:大小/时间/批次首时间戳跨越等
复制与一致性
副本角色与 ISR
- Leader/Follower:
ReplicaManager维护 - ISR(in-sync replicas):满足追赶与滞后阈值的副本集合
- 高水位 HW:最慢 ISR 的 LEO → 读一致性依据(只对 HW 以内可见)
消息队列对比表
| 特性维度 | Kafka | Pulsar | RabbitMQ | ActiveMQ | NATS | Redis Streams | AWS Kinesis | Google Pub/Sub |
|---|---|---|---|---|---|---|---|---|
| 架构模型 | 分布式日志,Broker 负责存储和消费 | 存储(BookKeeper)与计算(Broker)分离 | 基于 AMQP,Exchange 路由消息 | 基于 JMS,传统 Broker 模型 | 轻量级,基于订阅发布 | 基于 Redis 内部数据结构 | 托管服务,分片存储 | 托管服务,全球分布式 |
| 消息存储 | 持久化日志,分区存储 | BookKeeper 持久化日志 | 队列存储,支持持久化 | 队列存储,支持持久化 | 默认内存,可持久化 | Redis AOF / RDB | 托管存储(24h~7d 保留) | 托管存储(7d 保留) |
| 吞吐量 | 极高(百万级 TPS) | 极高(百万级 TPS) | 中等(十万级 TPS) | 中等(万级 TPS) | 高(十万级 TPS) | 中等(十万级 TPS) | 高,按分片扩展 | 高,自动扩展 |
| 延迟 | 低(ms 级) | 低(ms 级) | 较低(ms~几十 ms) | 较高(>10ms) | 极低(µs 级) | 低(ms 级) | ms~秒级 | ms~秒级 |
| 消息模型 | 流式(分区日志) | 同时支持流式 & 队列 | 队列 + 发布订阅 | 队列 + 发布订阅 | 发布订阅 | 流式结构 | 流式事件 | 发布订阅 |
| 扩展性 | 高,分区水平扩展 | 更高,支持无限水平扩展 | 一般,集群扩展有限 | 较差 | 高,支持集群 | 一般(依赖 Redis 集群) | 自动扩展 | 全球级扩展 |
| 典型场景 | 大数据、日志采集、流计算 | 云原生、多租户、大规模流处理 | 企业应用解耦、订单系统 | 传统企业应用、JMS 场景 | 微服务通信、IoT | 小规模数据流、轻量实时处理 | AWS 内大数据、日志流 | 跨区域分布式消息 |
| 运维复杂度 | 中等,需要 Zookeeper(新版本可选 KRaft) | 较高,需要管理 BookKeeper | 低 | 低 | 低 | 低 | 无需运维 | 无需运维 |
Resource
-
Books :2170922-EB-I_Heart_Logs.pdf
-
Paper List:KSQL: Streaming SQL Engine for Apache Kafka
-
Projects list:Apache Projects Directory
-
Presentation:Keynote Session | Kafka Summit London 2024
Question
-
Kafka是如何保障数据不丢失的?
-
如何解决Kafka数据丢失问题?
-
Kafka可以保障永久不丢失数据吗?
-
如何保障Kafka中的消息是有序的?
-
如何确定Kafka主题的分区数量?
-
如何调整生产环境中Kafka主题的分区数量?
-
如何重平衡Kafka集群?
-
如何查看消费者组是否存在滞后消费?
Business Example
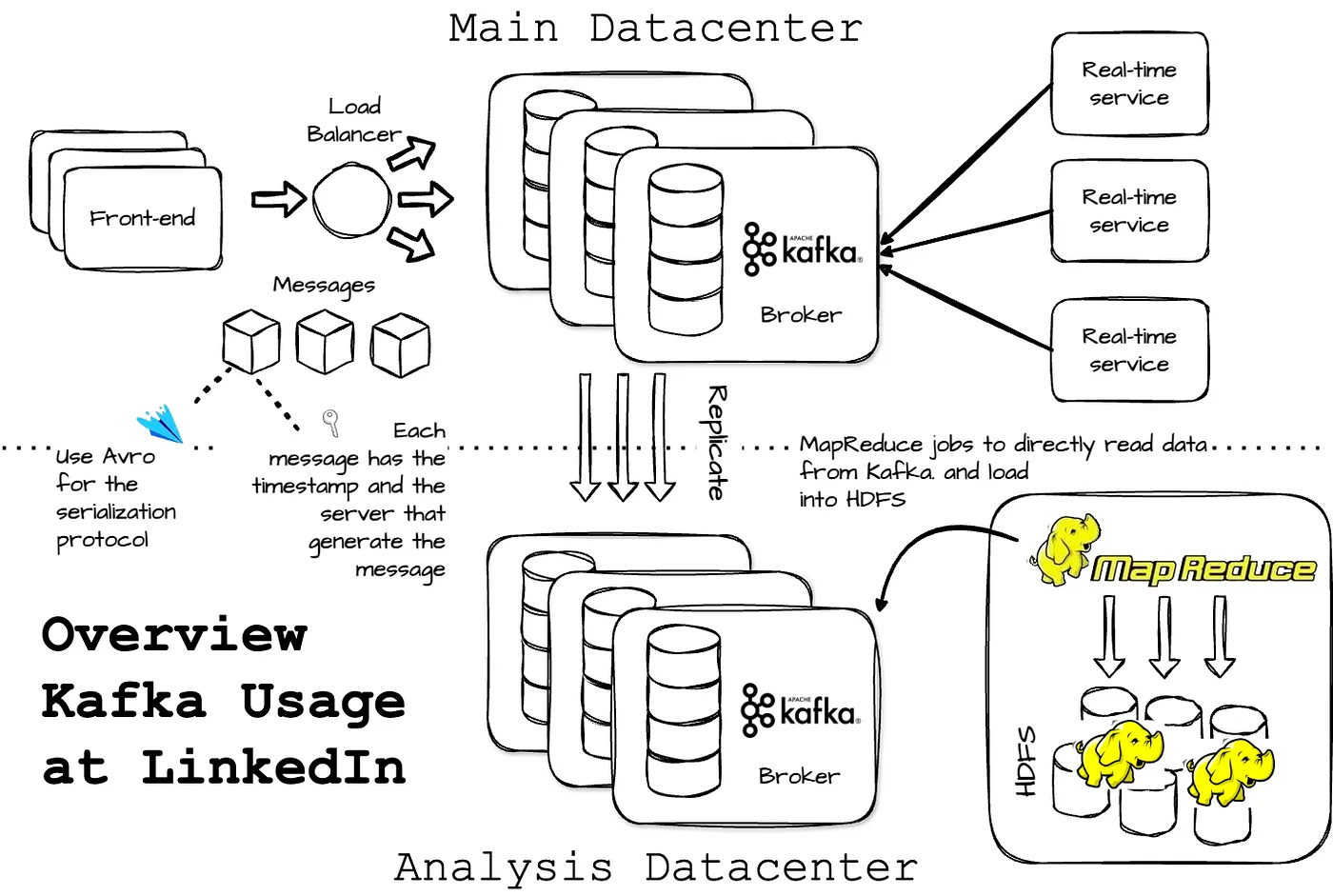 Kafka at LinkedIn
Kafka at LinkedIn
- 2019-05-17 快手万亿级别Kafka集群应用实践与技术演进之路 涉及 Kafka 使用场景以及Kafka 的 5 点重要改进:平滑扩容、Mirror 集群化、资源隔离、cache 改造以及消费智能限速
Reference
- The Log : What every software engineer should know about real-time data’s unifying abstraction - By Jay PKreps 201311
- Bufstream 几分钟内将 Kafka 消息传输到 Iceberg
- Monitoring Kafka Performance Metrics | Datadog
- Apache Kafka include Books and Papers
- What is Apache Kafka
- Know Streaming Kafka实时流运行平台,提供运维管控、监控告警、资源治理、多活容灾等核心场景
- Apache Kafka Overview. The terminology and the architecture. | by Vu Trinh | Data Engineer Things
- 源码的一些介绍
- Kafka原理
- Jmx’s Blog
Kafka Tools
- KAFKA EAGLE short name EFAK (Eagle For Apache Kafka, previously known as Kafka Eagle) is A DISTRIBUTED AND HIGH-PERFORMANCE KAFKA MONITORING SYSTEM By Mr Smartloli.
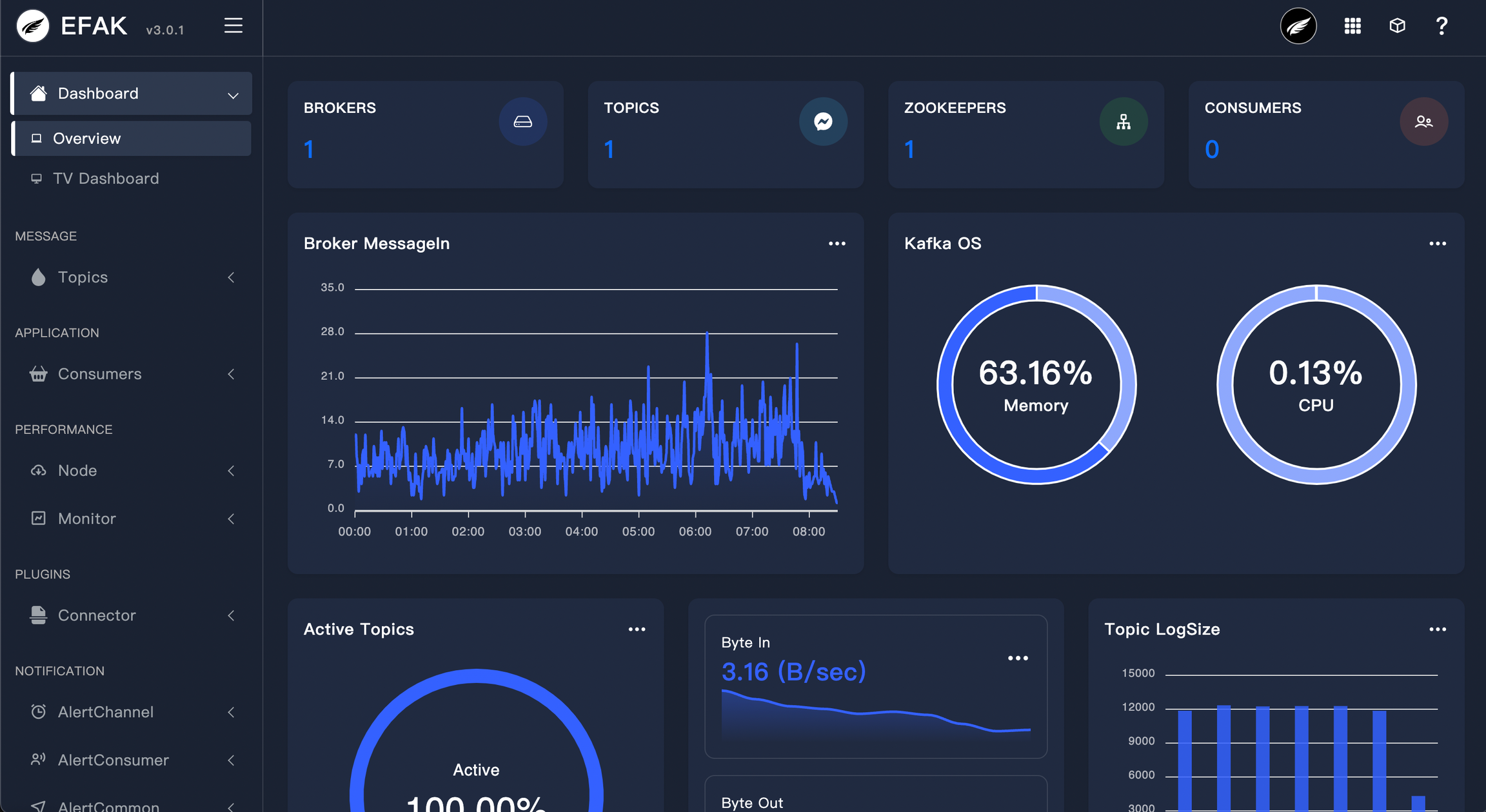 EFKA Dashboard UI
EFKA Dashboard UI
- CMAK is a tool for managing Apache Kafka clusters
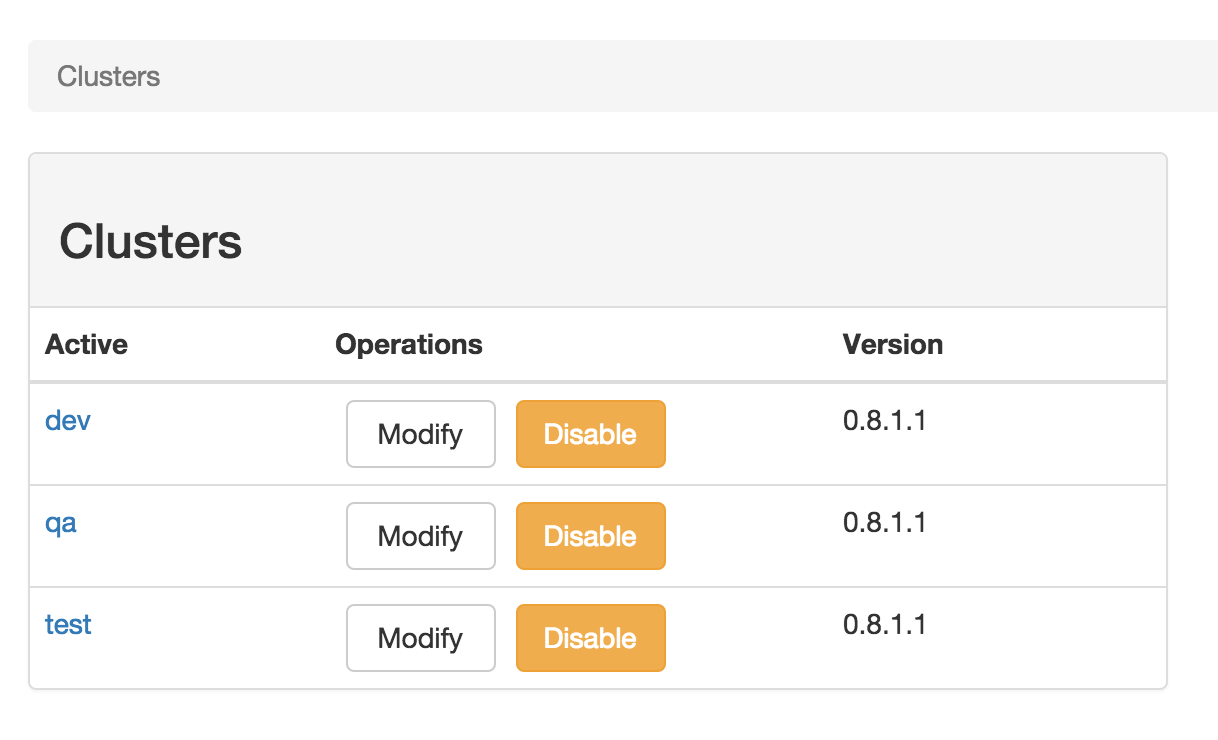 EMAK
EMAK
![]()