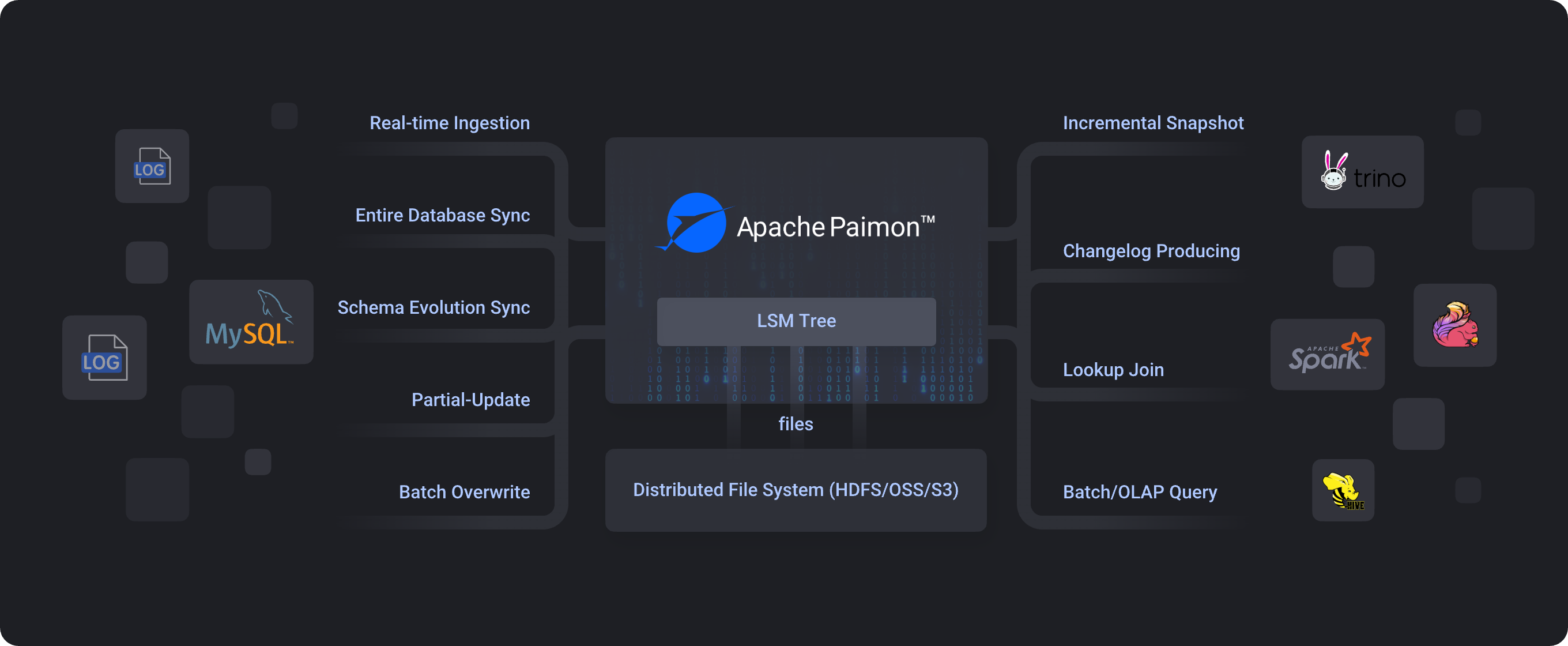
Overview
Apache Paimon is a streaming data lake storage system that provides ACID transactions, snapshot isolation, and unified batch/streaming processing across multiple compute engines including Flink, Spark, Hive, and Trino. It innovatively combines lake format capabilities with LSM-tree structures to enable real-time streaming updates within the lake architecture
Apache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。Paimon 采用开放的数据格式和技术理念,可以与 Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。
原理 & 功能
作为一种新型的可更新数据湖,Paimon具有以下特点
- 大吞吐量的更新数据摄取,同时提供良好的查询性能
- 具有主键过滤器的高性能查询,响应时间最快可达到百毫秒级别
- 流式读取在 Lake Storage 上可用,Lake Storage 还可以与 Kafka 集成,以提供毫秒级流式读取
文件布局
一个paimon标的全部文件存储在一个基础目录里,文件以分层的方式组织。如下图是paimon的文件部署,从Snapshot文件开始,Paimon文件读取器可以递归地访问表中的所有数记录
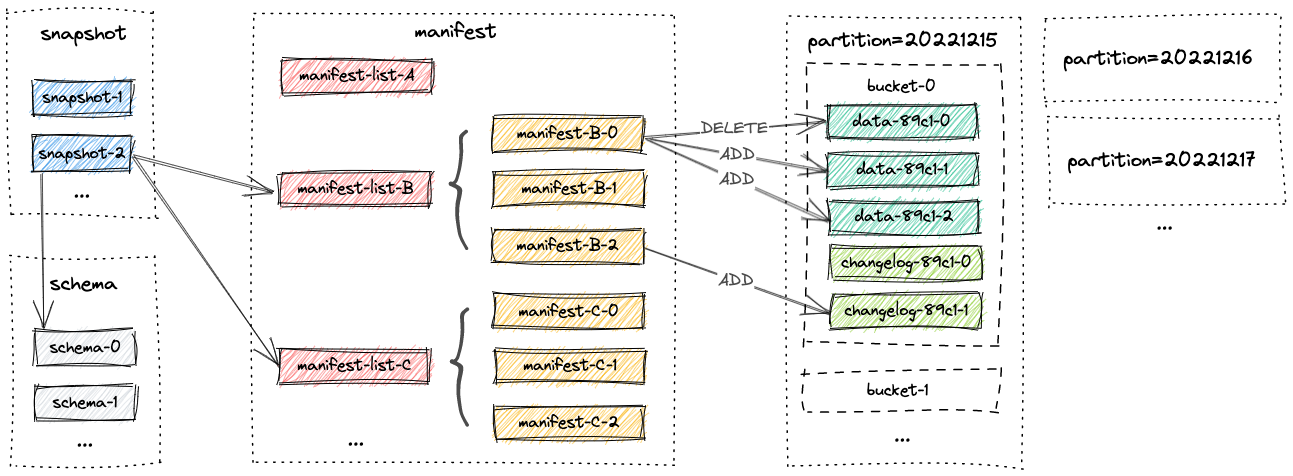
- Schema: 字段、主键定义、分区键定义和options
- Snapshot: 在某个特定时间点提交的所有数据的入口
- Manifest list: 包含若干个manifest文件
- Manifest: 包含若干data文件和changelog文件
- Data File: 包含增量记录
- Changelog File: 包含由changelog-producer生成的记录
- Global Index: bucket或partition的索引
- Data File Index: data文件的索引
Reference
- [Apache Paimon](https: //paimon.apache.org/)