 Apache ZooKeeper™ is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Apache ZooKeeper™ is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
下文以“ZK”称呼
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
- ZK 致力于开发和维护开源服务器,以实现高度可靠的分布式协调
- 发布/订阅模式的分布式数据管理与协调框架
架构
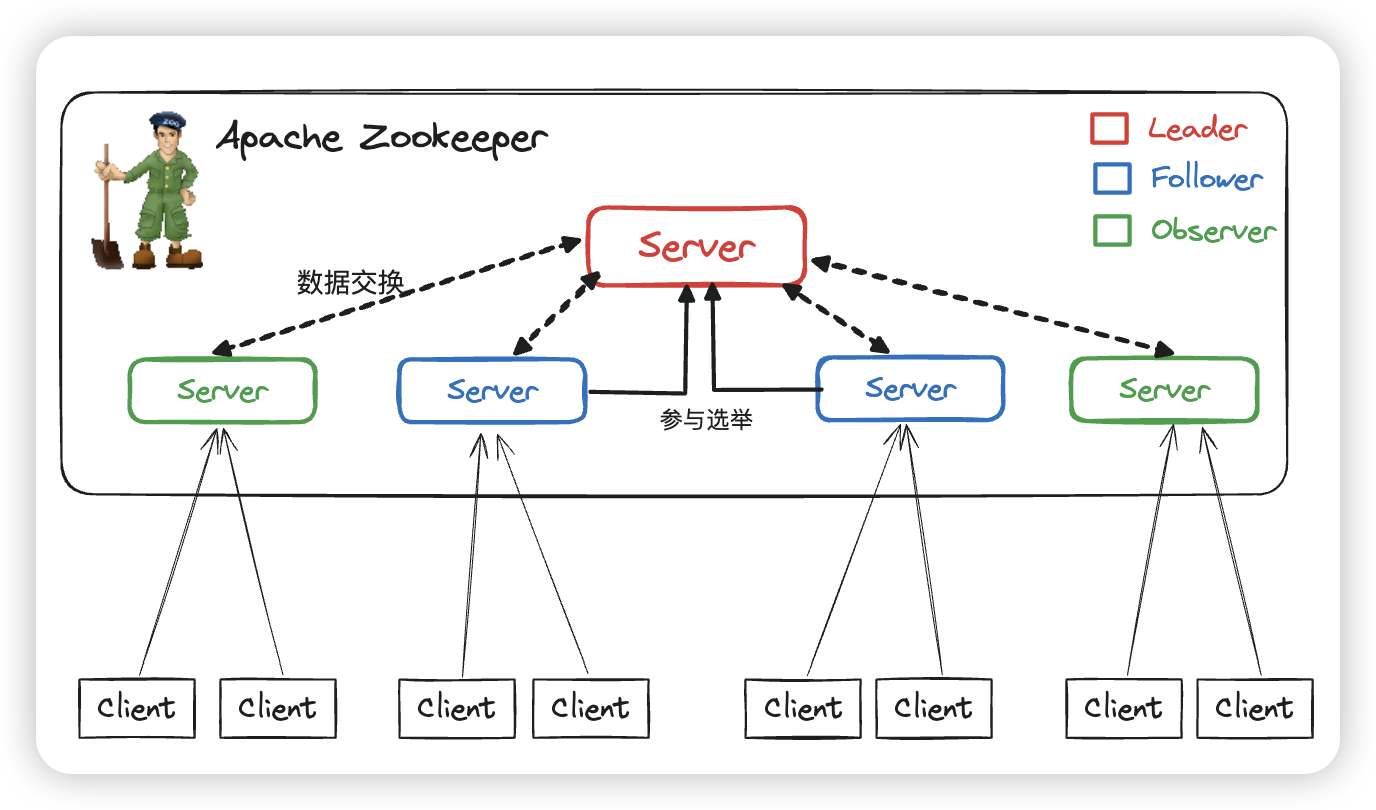
Leader
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性
- 集群内部各服务的调度者
- 管理投票工作 🗳️
Follower
- 处理客户端的非事务请求(读操作),转发事务(写请求)请求给Leader服务器
- 参与Leader选举投票
Observer
- 处理客户端的非事务请求,转发事务请求给Leader服务器
- 不参与任何形式的投票
- 3.3.0版本以后引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
Client
- 都保存同一份相同的数据副本,区别在于该请求是处理事物的还是非事物的
服务器工作状态
- LOOKING:寻找Leader状态。当服务器处于该状态时,它会认为当前集群中没有Leader,因此需要进入Leader选举状态
- FOLLOWING:跟随者状态。表明当前服务器角色是Follower
- LEADING:领导者状态。表明当前服务器角色是Leader
- OBSERVING:观察者状态。表明当前服务器角色是Observer
选举机制
ZK的默认的选举算法是FastLeaderElection,即投票过半则胜出
参选指标
- 服务器ID:被推举的Leader的SID
- 数据ID(zxid):被推举的Leader事务ID
- 逻辑时钟(electionEpoch):逻辑时钟,用来判断多个投票是否在同一轮选举周期中,该值在服务端是一个自增序列,每次进入新一轮的投票后,都会对该值进行加1操作
启动时选举
集群Down机后选举
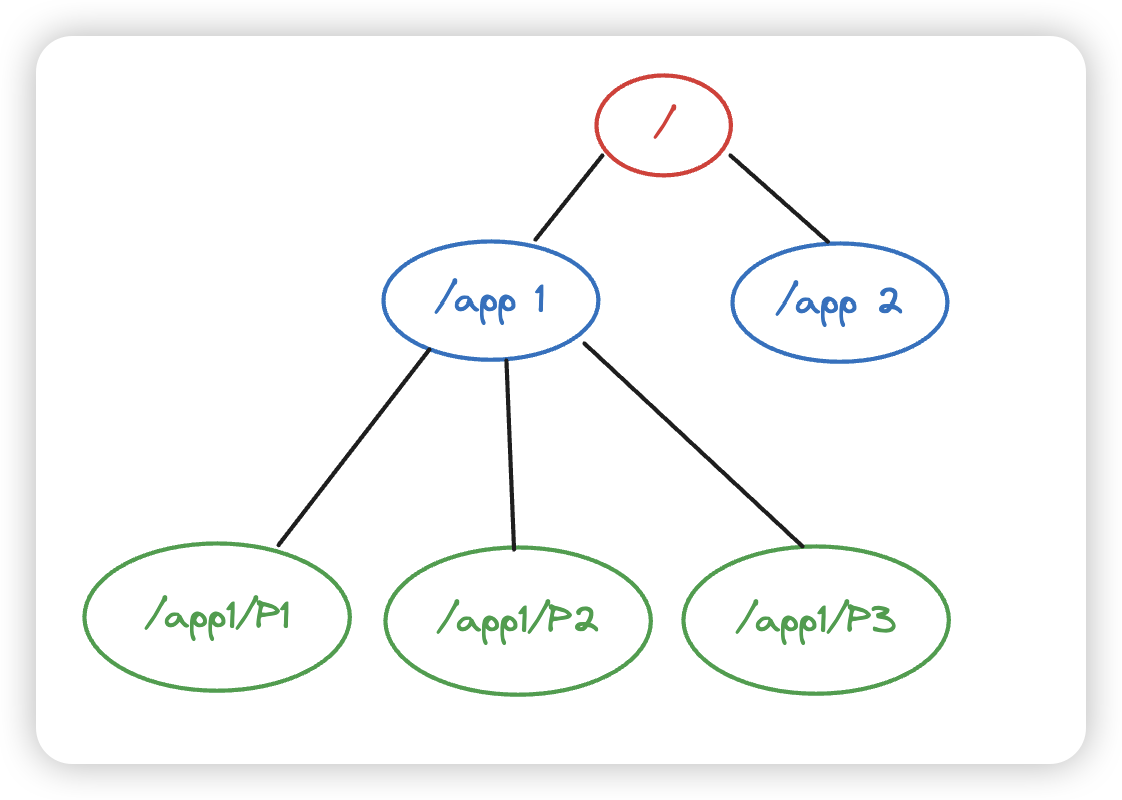
数据模型
应用场景
- 数据发布/订阅
- 负载均衡
- 命名服务
- 分布式协调/通知
- 集群管理
- Master选举
- 分布式锁
- 分布式队列
ZK与CP
ZK遵循的是CP原则,即一致性和分区容错性,牺牲了可用性
- 当Leader宕机以后,集群机器马上会进去到新的Leader选举中,但是选举时长在30s — 120s之间,这个选取Leader期间,是不提供服务的,不满足可用性,所以牺牲了可用性
部署模式
集群规则为2N+1台,N>0,即3台
- 单机模式
- 伪集群模式
- 集群模式